SOMA | arxiv 2026.03.25 | Paper Reading
SOMA: Strategic Orchestration and Memory-Augmented System for Vision-Language-Action Model Robustness via In-Context Adaptation
SOMA通过升级冻结的VLA策略实现无需参数微调的鲁棒上下文适应。具体而言,SOMA不微调VLA主干的前提下通过在线流程运行,包括对比式双记忆检索增强生成(RAG)、归因驱动的大型语言模型(LLM)编排器以及可扩展的模型上下文协议(MCP)干预,同时离线记忆巩固模块持续将执行轨迹提炼为可靠先验知识。实现异步离线记忆整合,持续精炼历史经验。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | Memory VLA | Memory Architecture | 2026-03-25 |
1.What?
SOMA是目前少有的无需微调即可为冻结VLA注入长期记忆的框架,模块化即插即用设计对工业部署极友好,双记忆对比架构打破了传统RAG"只学成功"的偏差,具有重要的方法论价值
2.Why?
在OOD任务中对抗感知噪声和环境变化的鲁棒性方面仍存在缺乏长期记忆、因果故障归因和动态干预能力而受到根本性限制
一种方法是用RAG和上下文学习,尽管这些方法能有效利用外部记忆,但其仅关注成功轨迹而忽略了失败案例的诊断价值,这凸显了构建能同时利用成功与失败经验进行对比指导的双重记忆结构的必要性
另一种方法利用LLM和VLM作为具备外部工具访问能力的高层规划器,但这些工作缺乏实现闭环适应所需的经验记忆与动态修正能力
3.How?
SOMA框架包含在线执行工作流与离线记忆巩固工作流。
a) 在线执行工作流:该在线工作流通过三个模块实现鲁棒的任务级适应:
- 双记忆RAG:从双记忆库中同时检索历史成功指导与结构化失败警示,为决策提供任务相关的上下文基础。
- 归因驱动的大语言模型编排器:通过归因引导的推理诊断执行障碍并生成针对性干预策略。
- MCP干预:通过可扩展工具接口执行编排策略,调节感知与语言输入以实现鲁棒的视觉语言行动推理。
b) 离线记忆巩固工作流:作为在线执行的补充,离线工作流执行双阶段记忆巩固。它将新观测到的成功与失败轨迹提炼为结构化记忆,并更新双记忆库,从而在不更新参数的情况下实现持续改进。
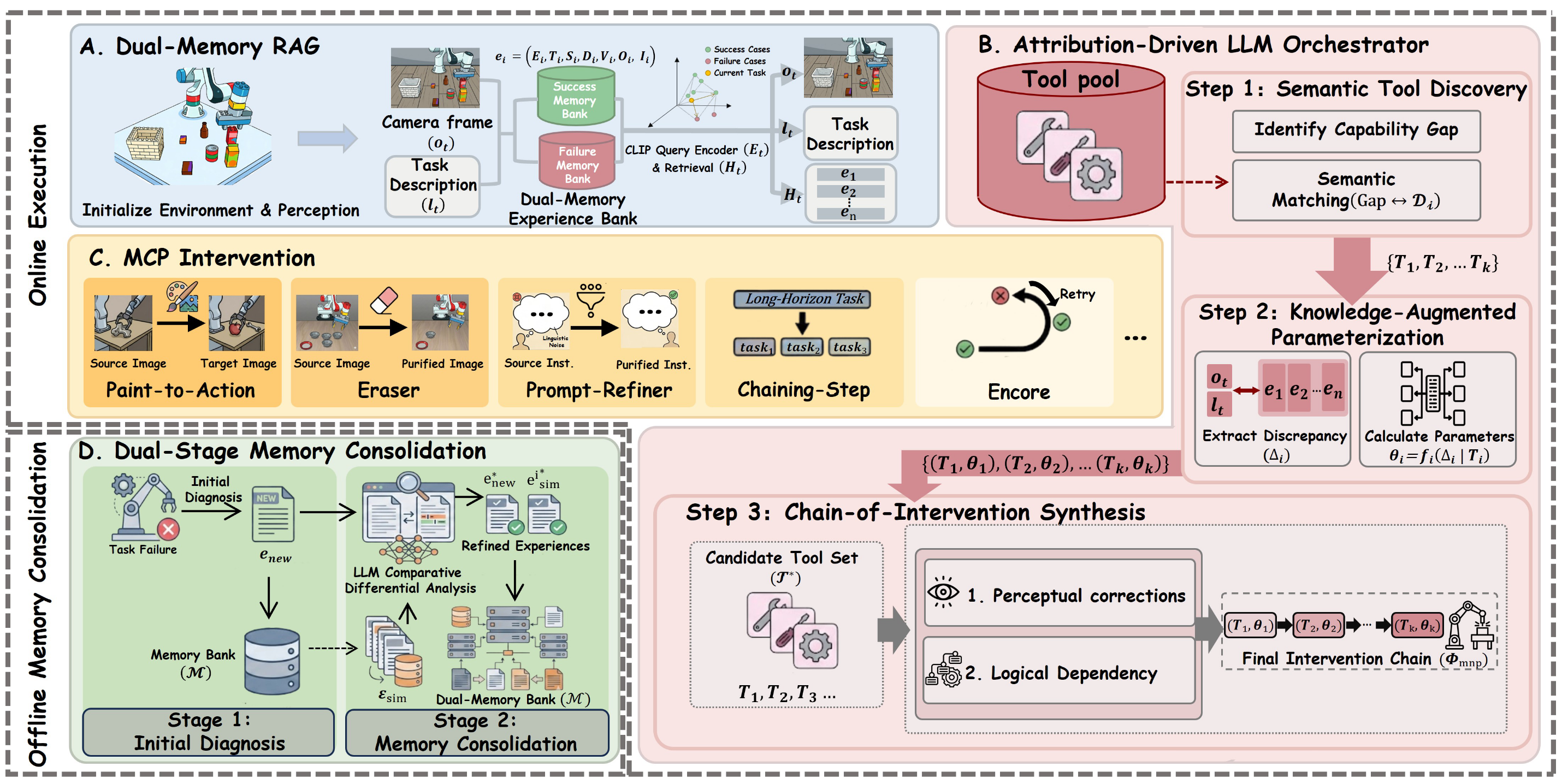
A. 双记忆RAG
对应图3中A部分,本模块实现了一个检索增强的双记忆库,为下游决策提供结构化历史上下文,将大语言模型的推理锚定于先前的成功与失败经验。与传统RAG系统不同,我们的记忆设计在两个互补维度上具有双重性:(1)明确分离成功与失败经验以实现对比归因;(2)每条经验在巩固阶段(见第三-D节)经历两阶段归因处理,从而持续优化存储信号。我们首先描述双记忆经验库的构建,再介绍基于其构建的检索机制。
- 双记忆存储设计:我们构建了一个双分区记忆库:
M = Msucc ∪ Mfail, (1)
其中Msucc存储成功的干预轨迹作为正向指导,Mfail则归档失败尝试及结构化归因信号作为负向证据。这种显式分离支持有效策略与需规避模式之间的对比推理。该双分区设计具有实证依据:如第三-A节消融分析所示,仅使用成功或仅使用失败经验会导致不稳定或低效的干预规划,而同时保持两个分区可减少推理轮次与方差,提供更强的决策锚定。
每条经验条目ei ∈ M以半结构化模式存储,包含固定核心模式与可扩展辅助字段:
ei =(Ei, Ti, Si, Di, Vi, Oi, Ii ) (2) Ei, Ti, Si, Di, Vi, Oi,为固定模式
• Ei:任务实例的多模态嵌入;
• Ti:自然语言任务描述;
• Si ∈ {0, 1}:成功标识符;
• Di:诊断标注(失败案例非空);
• Vi:执行视频的关键帧表示;
• Oi:以对象-属性对构成的结构化场景;
• Ii:可扩展的结构化元数据包。
元数据包Ii提供灵活的工具执行模式,包含关键帧范围、成功最大步数、回滚等参数。随着工具或推理信号的发展可追加新字段,平衡模式稳定性与表征灵活性。
2)基于相似度的检索策略:我们采用预训练的CLIP编码器[20] E(·,·)将当前任务上下文(初始观测ot与指令lt)投射至联合嵌入空间。检索过程形式化表示为:Ht = Top-k Sim E(ot, lt), {Ei | ei ∈ M},(3)
Ht包含成功范例与失败先例,为归因驱动推理提供正向引导与负向反事实参照。三元输入(Ht, ot, lt)为大语言模型编排器诊断差异并序列化干预工具提供了必要的基础支撑。
B. 归因驱动的大语言模型编排器
如图3B所示,大语言模型编排器模块构成SOMA的决策核心。我们采用Qwen3-VL-32B作为底层推理引擎,利用其先进的多模态理解与逻辑推理能力,通过模型控制协议诊断执行故障并编排干预措施。
1)语义工具发现与意图对齐:大语言模型通过度量当前状态ot与检索原型Ht之间的能力差距来识别干预需求。给定语义工具描述{Di}N i=1,系统执行零样本匹配以选择候选工具集:T1:k = Match ∆g, {Di}N i=1,∆g = Gap(ot, Ht),(4)
筛选出功能与诊断故障原因相匹配的工具。
- 知识增强参数化:完成工具选择后,大语言模型从多模态上下文差异∆中推导出执行参数θi:θi = f(∆i | Ti),∆i = Gap(ot, lt, Ht | Ti),(5) 其中f表示工具特定值的映射函数。具体而言,∆刻画了当前观察ot与指令lt在视觉、语义及时间维度上相对于历史先验Ht的偏差。
最终输出为一组参数化干预措施:T∗ = {(T1, θ1), (T2, θ2), …, (Tk, θk)},(6)

- 干预链合成:随后,大语言模型将工具合成为有序的干预链:Φmcp = Orchestrate(T∗) = (T1, θ1) → (T2, θ2) → · · · → (Tk, θk),(7)
该编排遵循两条原则:
- 感知优先:感知校正(如Paint-to-Action、Eraser)优先于物理恢复(如Encore),以避免因感知错误导致的重复失败。
- 逻辑依赖:因果干扰消除在下游推理与执行之前实施。例如,在联合视觉偏移与执行停滞的情况下,大语言模型生成Paint-to-Action → Encore,使感知校正先于回滚操作。
C. MCP干预模块
如图3C所示,该模块通过感知或物理动作执行干预链Φmcp。我们针对常见视觉语言智能体故障(如分布偏移与因果干扰)实例化了五种MCP工具,同时保持对新故障类型的即插即用扩展性。
-
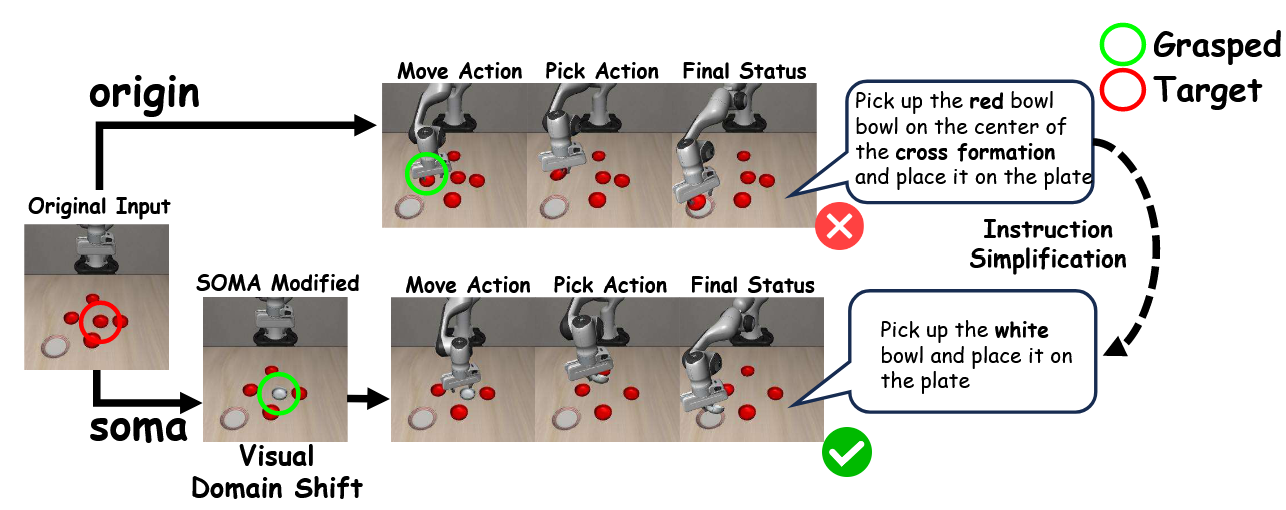
绘画至行动:视觉域迁移:绘画至行动执行非参数化域适应:o′ t = 绘画至行动(ot, θdist),(8) 具体实现通过视觉叠加与纹理替换完成。大型语言模型推导θdist,SAM3 分割目标区域,并通过高对比度掩码或来自成功轨迹(抓取成功)的纹理来缓解域偏移(图4)。
-
因果混淆消除器:通过参数θconf移除无关物体:o′t = Eraser(ot, θconf), (9)。该模块利用大语言模型从ot和Ht中识别干扰物,SAM3算法提取掩膜,随后通过OpenCV Telea修复技术在执行策略推理前将其消除(图5)。
-
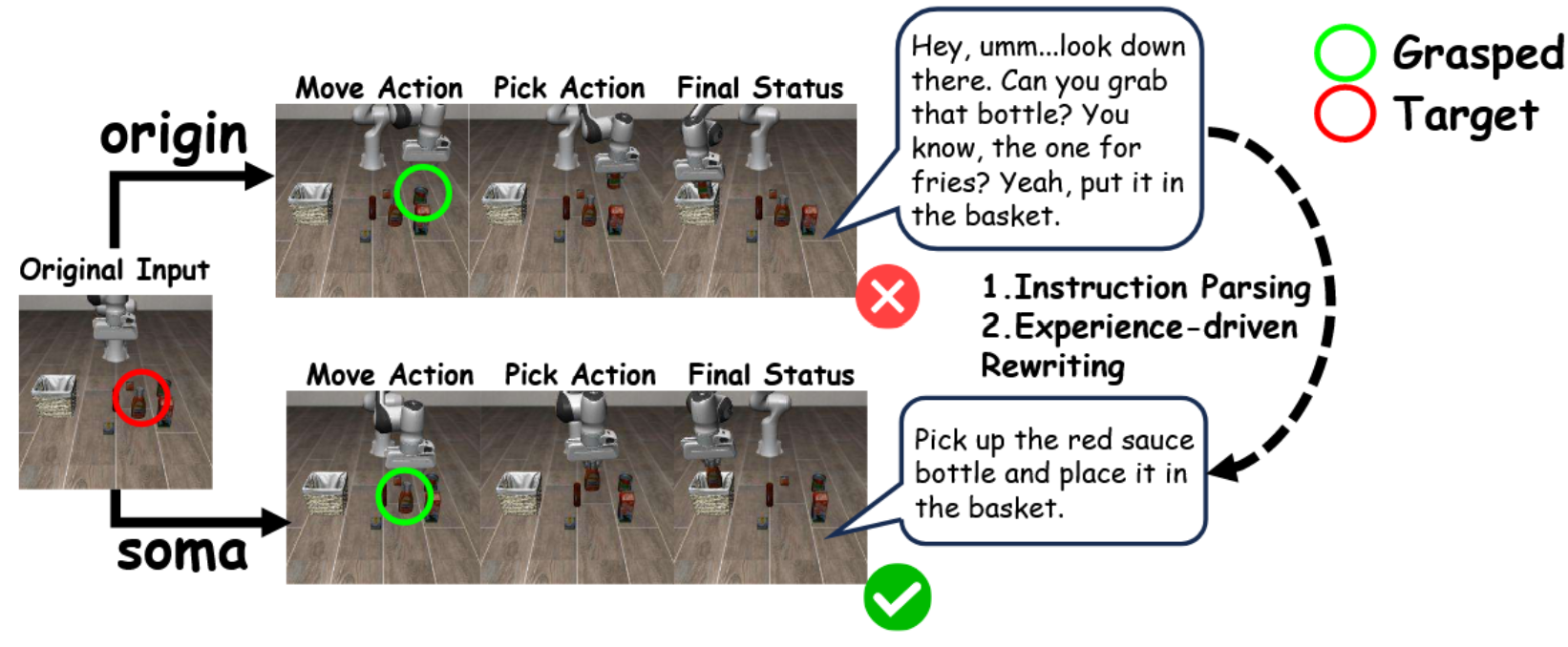
提示词优化器:针对语言歧义问题,该模块对噪声指令进行规范化处理:l′t = Prompt-Refiner(lt, θlang), (10)。其中大语言模型将模糊指令lt重写为与策略对齐的标准化任务描述,其改写模板源自历史成功记录Ht(例如将口语化指令重写为“拾取……并放置……”的简洁形式,如图6所示)。
-
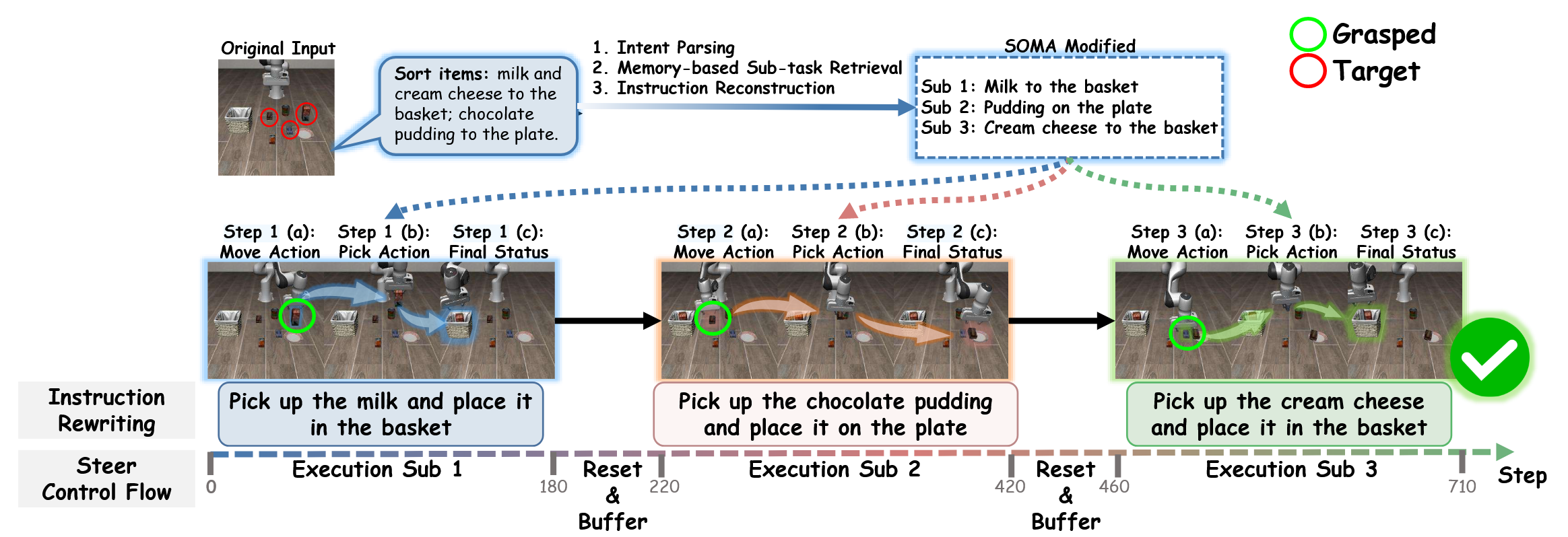
链式步进-时间复合:链式步进缩短执行跨度:A′ seq = 链式步进(Aseq, θchain),(11) 大语言模型利用 Ht 将宏观序列 Aseq 分解为对齐的子任务,并从 θchain 分配时间边界(特别是 Ne, Nb)。将 Aseq 替换为 A′seq 可缩短执行片段,缓解长跨度情境退化问题(例如,如图1所示,长任务被拆分为更短的子任务,并在其间设置“重置与缓冲”)。
-
重演机制:执行停滞处理:Encore通过关键状态恢复解决死锁问题:s′ t = Encore(st, θstuc), (12) 其中θstuc(源自历史故障记录Ht)定义了重试边界[ss, se]与等待时长Nw。该工具通过平均逆向轨迹重置计数器并回滚状态;若时间跨度验证失败,则触发从关键帧ss开始的"重置并重试"流程(图7)。
D. 双阶段记忆巩固
如图3D所示,该模块通过两阶段归因机制将最新执行轨迹整合至双记忆库M中。
- 阶段一:初始诊断:任务终止时,大语言模型执行初始诊断:enew = InitDiag(ot, Traw), (13) 并将新经验存储至记忆库:M = M ∪ {enew}, (14)
- 阶段二:记忆巩固:记忆巩固模块检索出前N个相似历史经验Esim = {e1 sim, . . . , eN sim}进行跨任务联合优化,其形式化表示为:{e∗ new, e1∗ sim, . . . , eN∗ sim } = MemConsol(enew, Esim), (15) 其中每个e∗为更新后的经验元组。大语言模型通过批量级差分分析修正历史失败描述,并利用新证据优化修正方案,从而实现对记忆库M的迭代自我校正,而非单调扩张。
4.Takeaways:
VLA模型的OOD故障主要源于感知与协调能力的局限,而非运动功能缺陷
局限性&未来工作:
未来工作将扩展MCP工具库以覆盖更广泛的故障模式,并探索前沿多模态模型以进一步提升故障归因的细粒度。
SOMA | arxiv 2026.03.25 | Paper Reading