ReMem | arxiv 2026.03.13 | Paper Reading
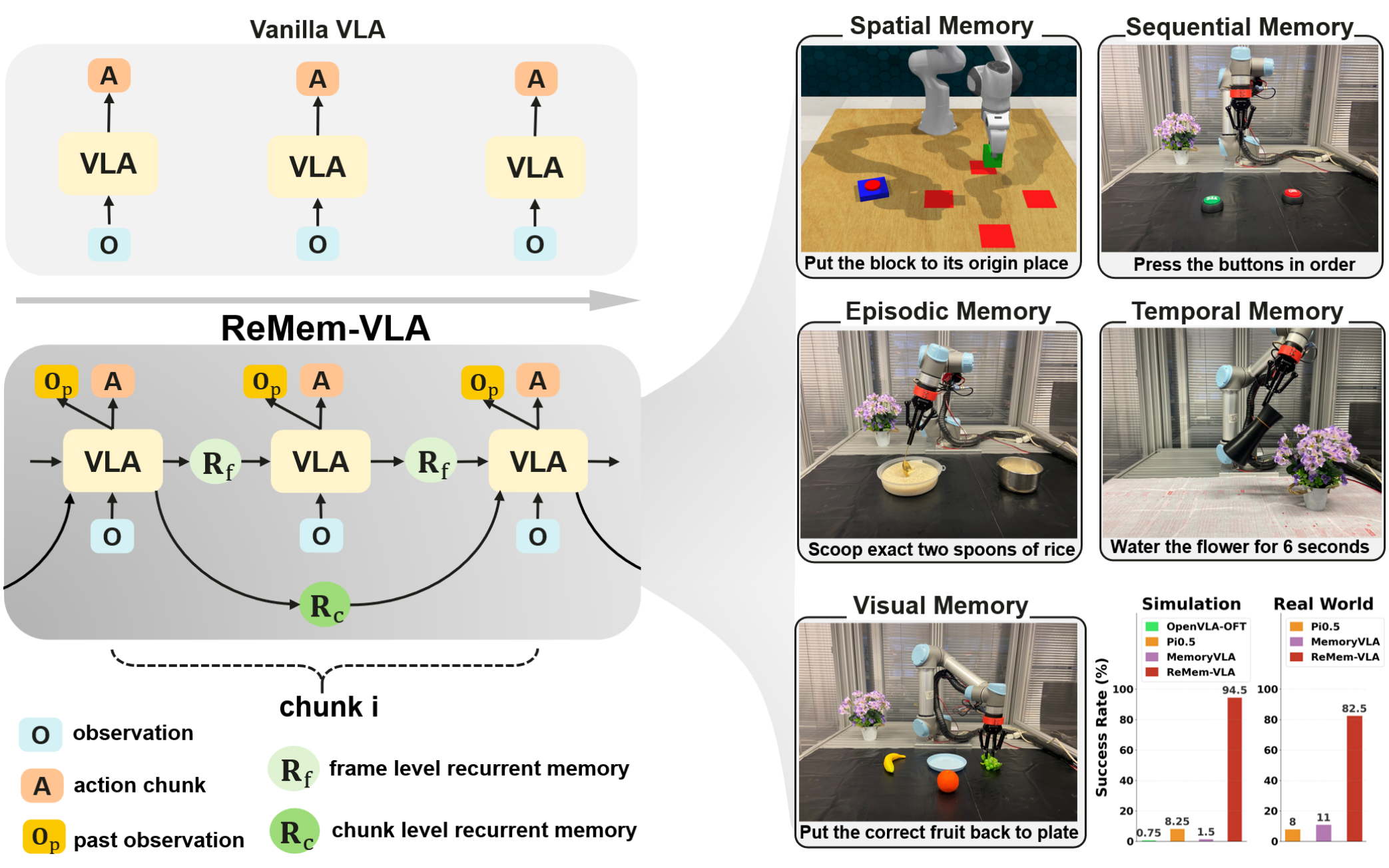
ReMem: Empowering Vision-Language-Action Model with Memory via Dual-Level Recurrent Queries
ReMem | arxiv 2026.03.13 | Paper Reading
ReMem: Empowering Vision-Language-Action Model with Memory via Dual-Level Recurrent Queries
SOMA | arxiv 2026.03.25 | Paper Reading
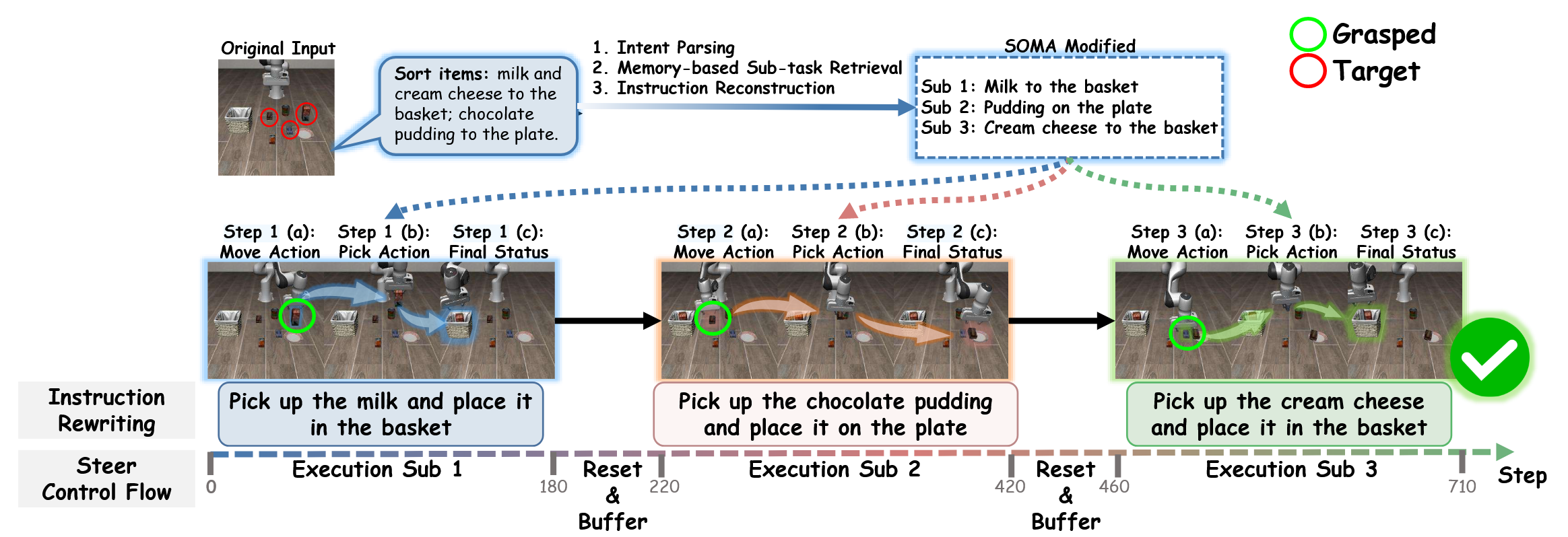
SOMA: Strategic Orchestration and Memory-Augmented System for Vision-Language-Action Model Robustness via In-Context Adaptation
MemER | arxiv 2025.10.23 | Paper Reading
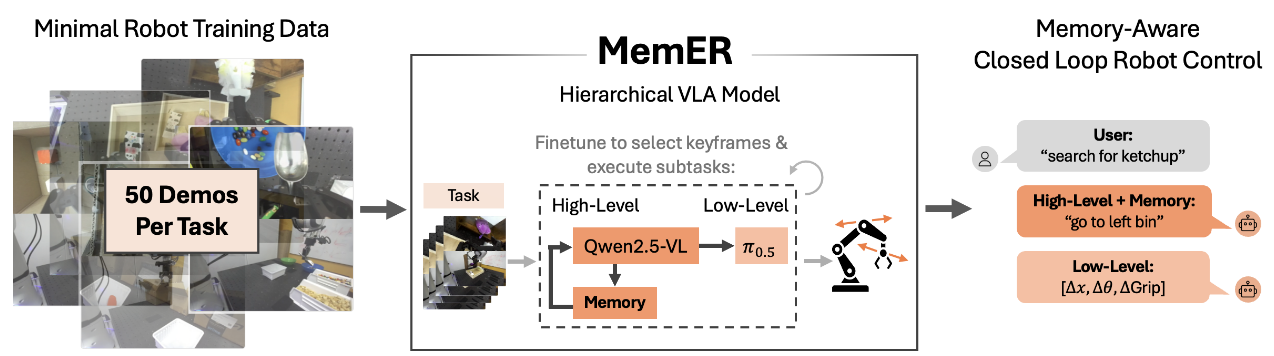
MEMER: SCALING UP MEMORY FOR ROBOT CONTROL VIA EXPERIENCE RETRIEVAL
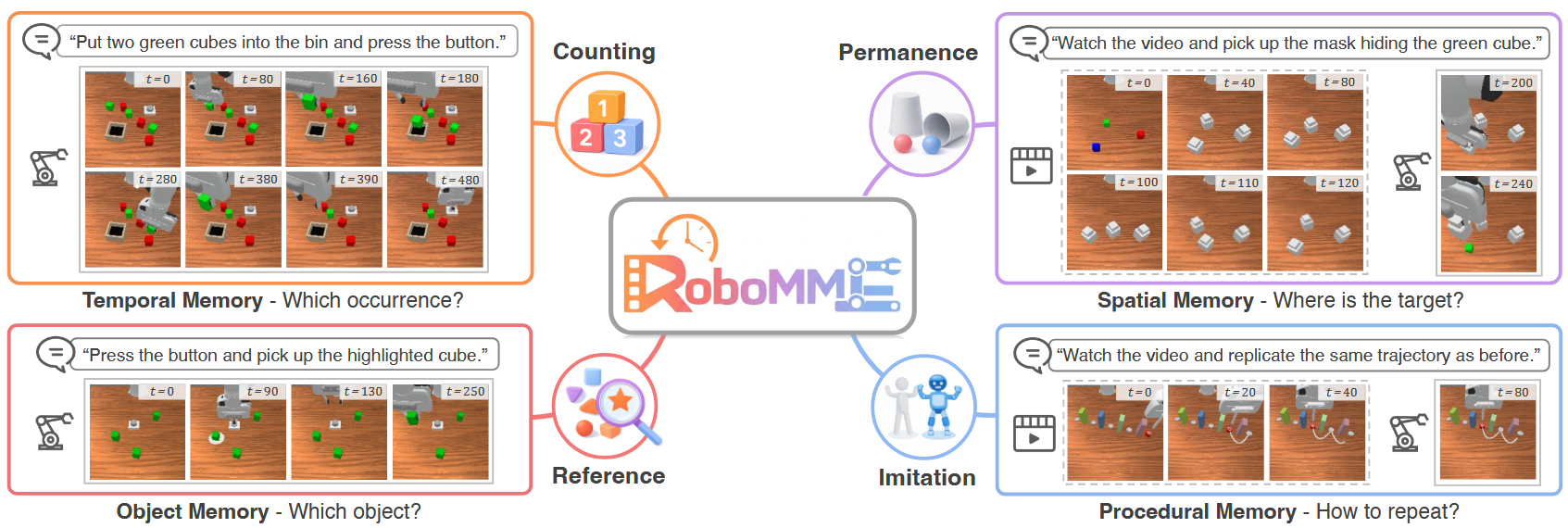
RoboMME | arxiv 2026.03.04 | Paper Reading
RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
###密歇根大学、斯坦福大学和Figure AI联合完成的研究,创造了世界首个机器人记忆能力评估系统RoboMME,包含16个测试任务和77万训练步骤。
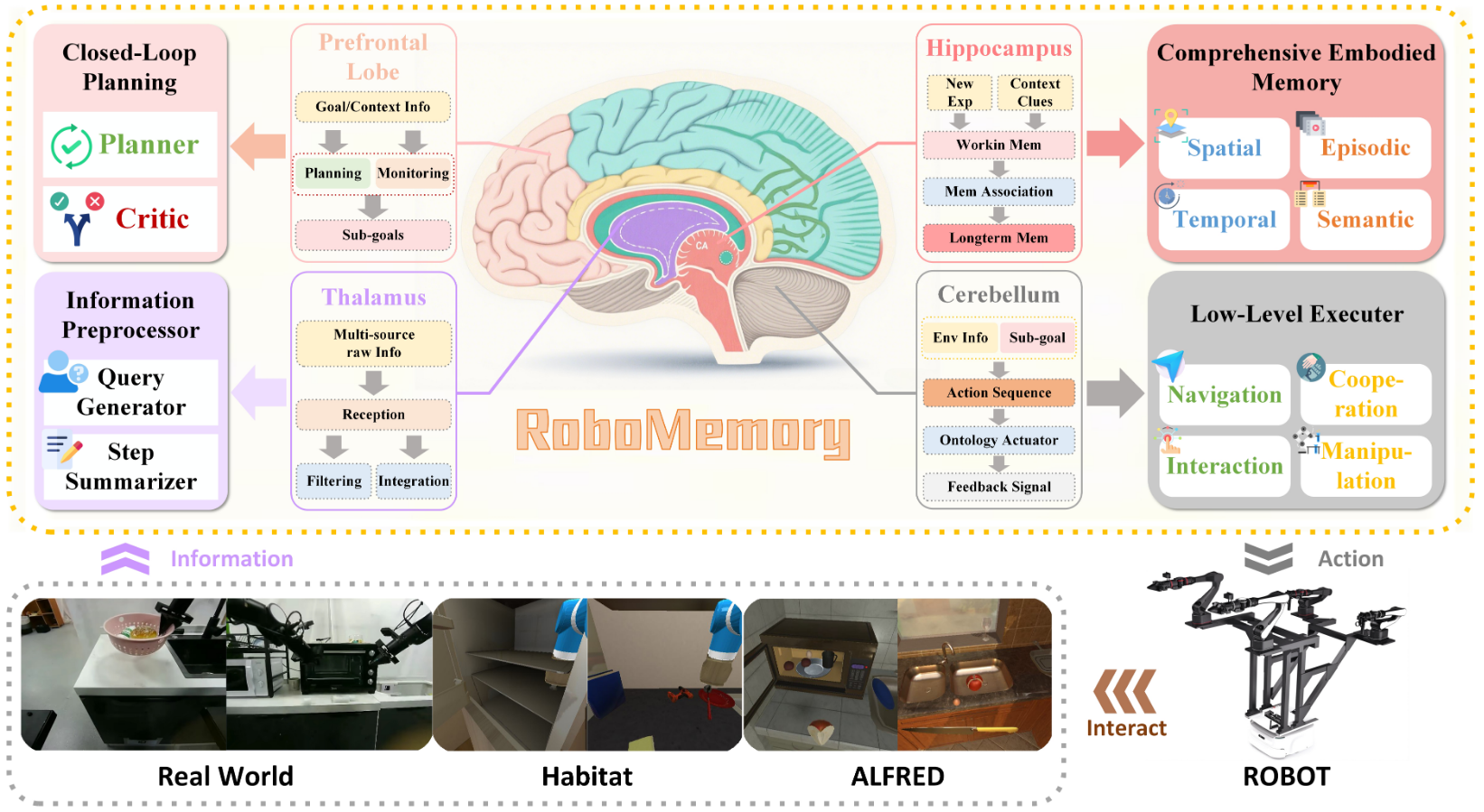
RoboMemory | arxiv 2026.02.04 | Paper Reading
RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Interactive Environmental Learning in Physical Embodied Systems
###RoboMemory 通过模仿大脑结构,设计了四个协同工作的模块,特别是其创新的「终身具身记忆系统」,该系统包含空间、时间、情景和语义四种并行工作的记忆模块,极大地提升了机器人的学习效率和反应速度

RMBench | arxiv 2026.03.01 | Paper Reading
RMBench: Memory-Dependent Robotic Manipulation Benchmark with Insights into Policy Design
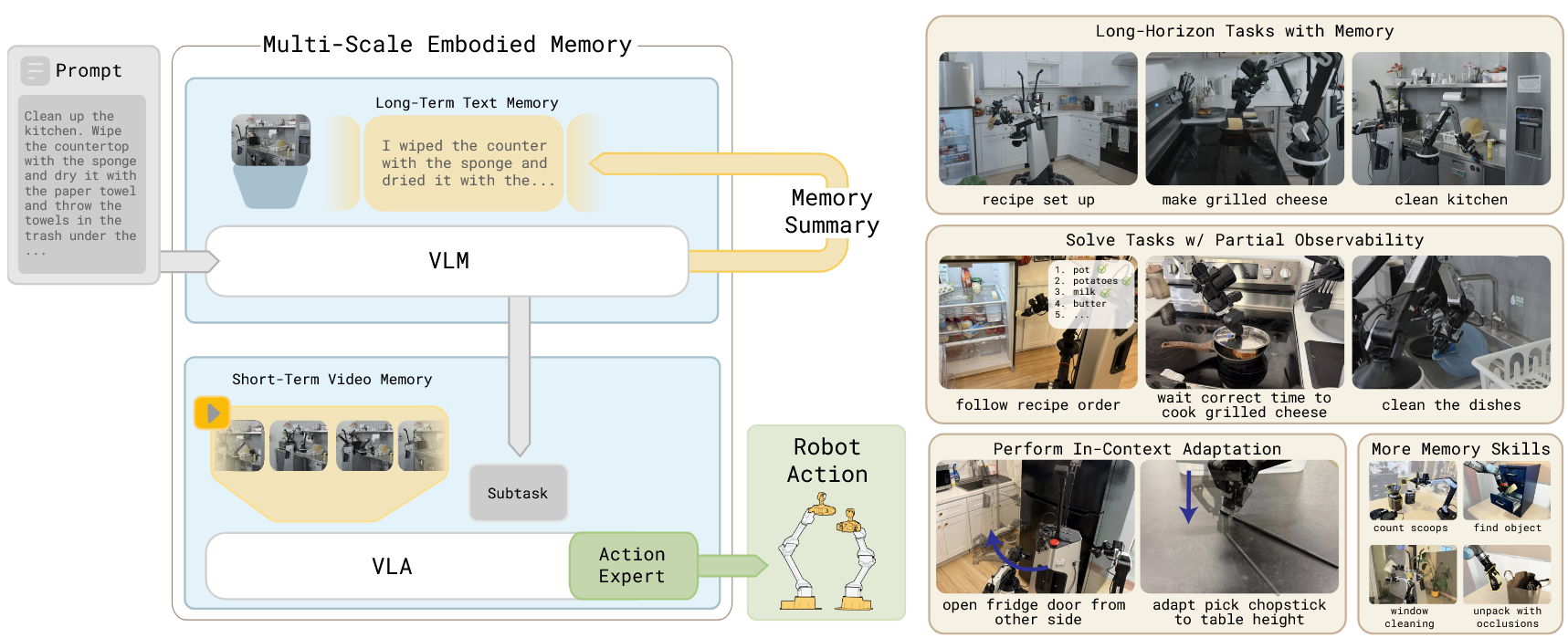
MEM | arxiv 2026.03.03 | Paper Reading
MEM: Multi-Scale Embodied Memory for Vision Language Action Models
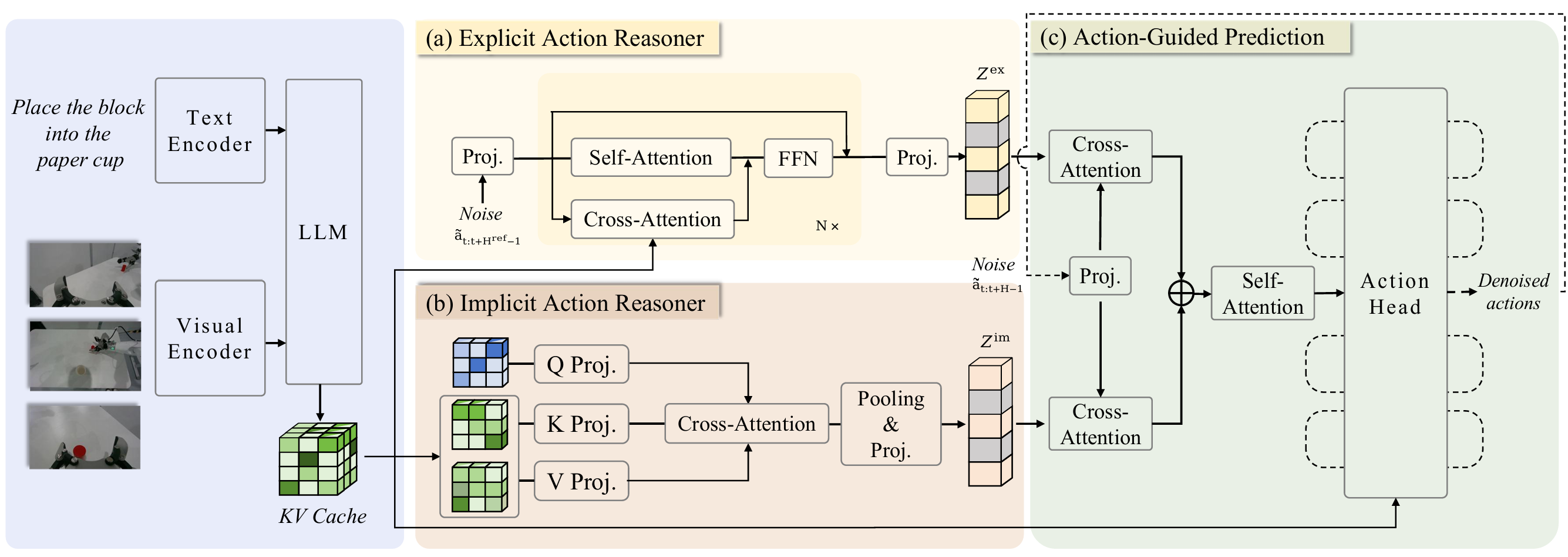
ACoT-VLA | arxiv 2026.01.16 | Paper Reading
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models

InternVLA-A1 | arxiv 2026.01.05 | Paper Reading
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
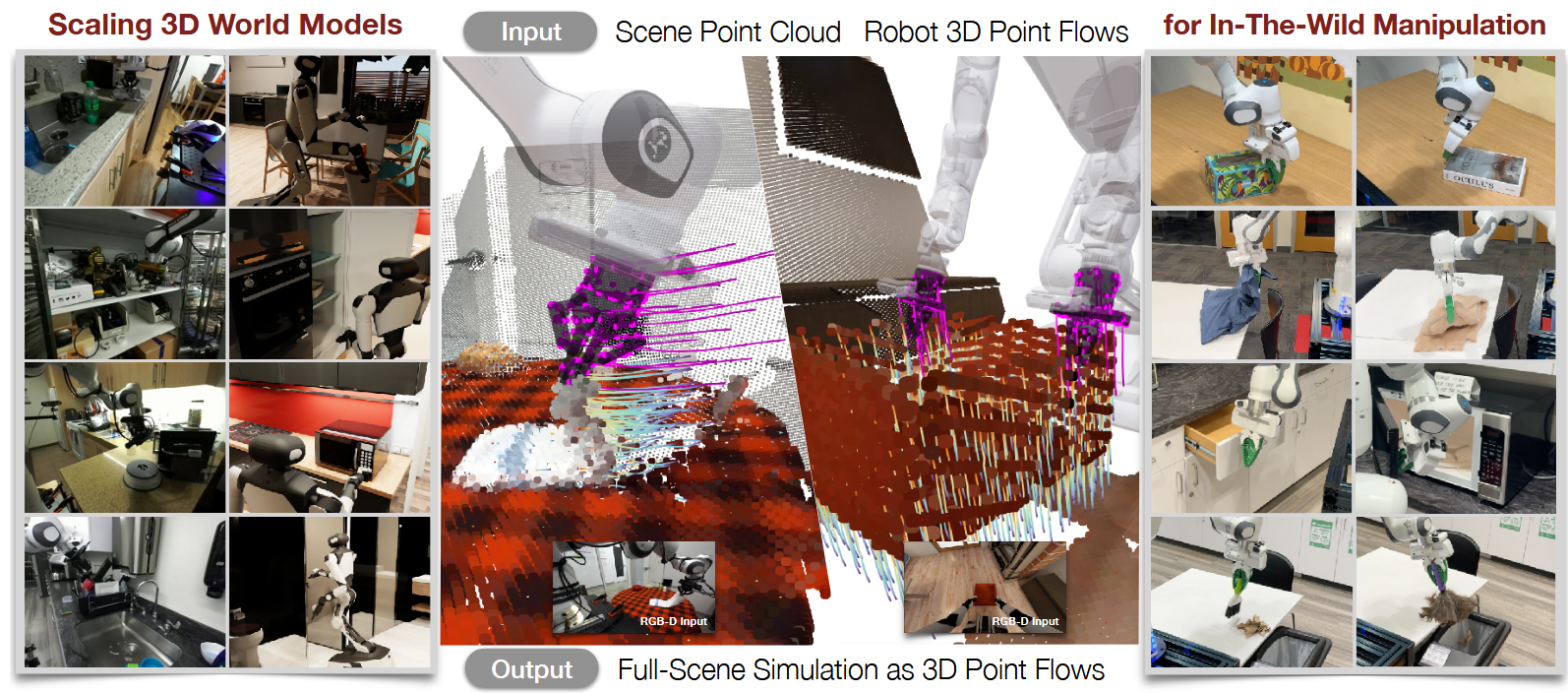
PointWorld | arxiv 2026.01.07 | Paper Reading
PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation