MemER | arxiv 2025.10.23 | Paper Reading
MEMER: SCALING UP MEMORY FOR ROBOT CONTROL VIA EXPERIENCE RETRIEVAL
MemER 摒弃了 “暴力扩展上下文长度” 的传统思路,转而让机器人学会 “主动筛选并记忆关键信息”。核心设计围绕 “分层政策” 与 “动态关键帧管理” 展开,保留了现有VLA模型的优势,同时针对性解决了长时序记忆的痛点。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | Memory VLA | Memory Architecture | 2025-10-23 |
1.What?
MemER:一个分层策略与经验检索机制,首次让机器人在需要分钟级记忆的真实场景任务中实现高效推理。
核心创新:分层架构 + 智能记忆检索
2.Why?
- 计算效率与记忆长度的冲突。直接处理连续数百帧图像会使训练成本激增,且部署时延迟严重超标,这使得传统端到端政策只能放弃长时序记忆,仅依赖当前或极短序列的观测数据。
- 数据冗余与关键信息的脱节。长序列观测容易引入 “虚假相关性”,让政策过度依赖演示数据中的偶然特征(如特定光照下的物体阴影)。当实际部署环境与演示场景存在差异时,政策会因状态分布偏移导致性能持续退化,且观测序列越长,这种退化越严重。
- 通用模型与机器人场景的适配鸿沟。现有VLM虽具备视频理解能力,但缺乏解读机器人特定感知线索的能力。例如无法识别 “夹爪未完全闭合” 这类与任务成败相关的细节,更无法将视频理解能力转化为长时序操纵任务中的记忆管理能力。
3.How?
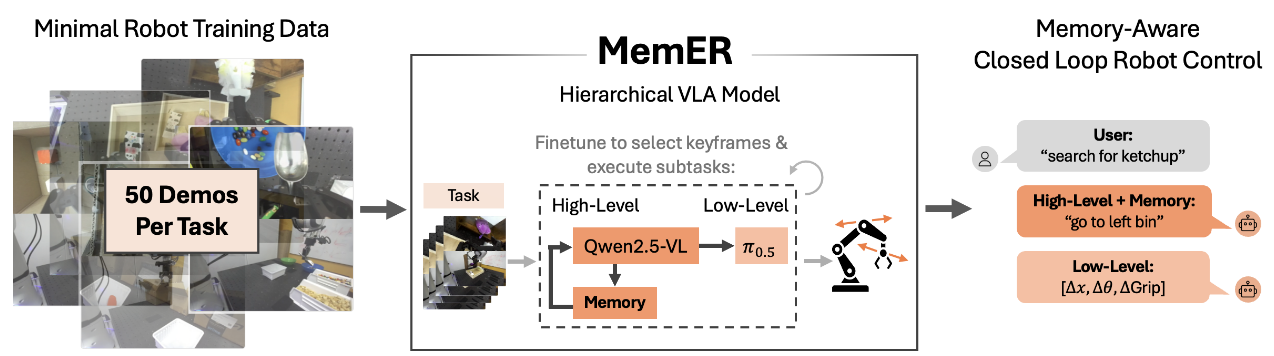
MemER 将机器人政策拆分为高层与低层两个协同模块,形成 “记忆决策 - 动作执行” 的闭环:
高层政策(记忆决策者) 基于Qwen2.5-VL-7B-Instruct 微调而成,核心职责是 “管理记忆” 与 “分解任务”。
它接收三部分输入:各相机的最近 N 帧图像(实验中 N=8,即 “近期上下文”)、原始任务指令(如 “寻找番茄酱”)、历史筛选的关键帧集合 Kₜ(最多 8 帧,来自整个任务周期)。
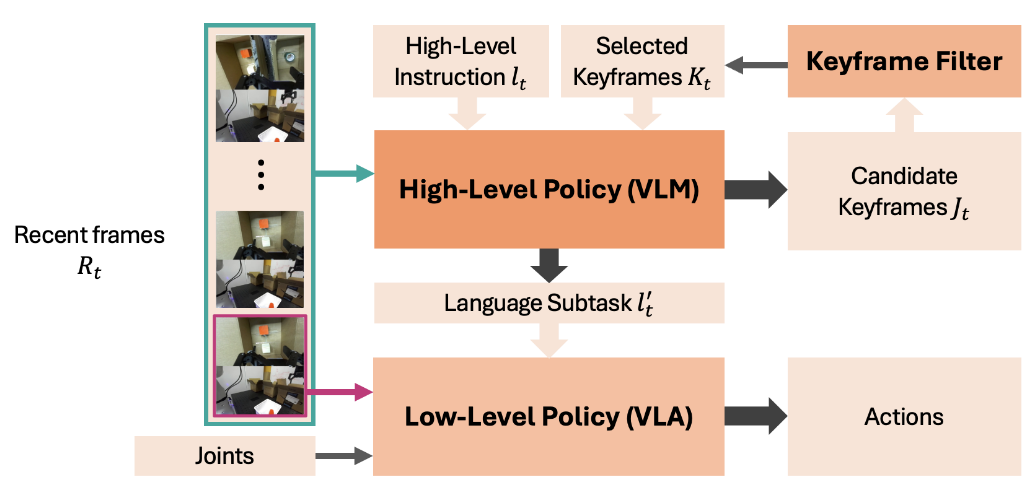
MemER 架构一览。高层策略处理任务指令、已选关键帧(若有)及基座与腕部相机近期图像,生成低层语言子任务与候选关键帧(若有);低层策略依据子任务、当前图像及机器人关节状态生成动作;候选关键帧经过滤器处理后,得到后续推理的已选关键帧。
输出则包含两部分:一是当前子任务指令(如 “查看右侧箱子”),二是从近期上下文筛选出的候选关键帧 Jₜ。该模块的**关键优势在于利用了 Qwen2.5-VL-7B-Instruct 的预训练视频理解能力,通过微调,模型能自动识别哪些帧包含任务关键信息(如箱子内部物体、物体原始位置),无需额外设计特征提取器。**实验中,仅需 50 条遥控演示数据与子任务标注,就能让模型适配机器人记忆需求。
低层政策(动作执行者) 基于π₀.₅模型微调,专注于 “高精度高频控制”。它接收当前图像、机器人本体感受数据(关节角度、夹爪状态)与高层输出的子任务指令,直接输出关节速度等动作信号,处理运动学控制、抓取精度等机器人特有挑战。由于低层政策仅需关注当前子任务,无需处理长序列数据,能以 2Hz 的频率输出动作,满足实时控制需求。
这种拆分让高层专注于长时序记忆推理,避免陷入高频控制的细节;低层专注于实时动作执行,无需负担记忆管理的计算成本,两者通过 “子任务指令” 衔接,既保证了记忆的有效性,又不牺牲控制响应速度。
关键帧管理:用聚类算法浓缩 “有效记忆”
高层政策筛选关键帧的核心是 1D 单链接聚类算法,该机制确保机器人能从数千帧的任务周期中,动态保留最有价值的视觉信息,避免记忆库无限膨胀。具体流程分为三步:
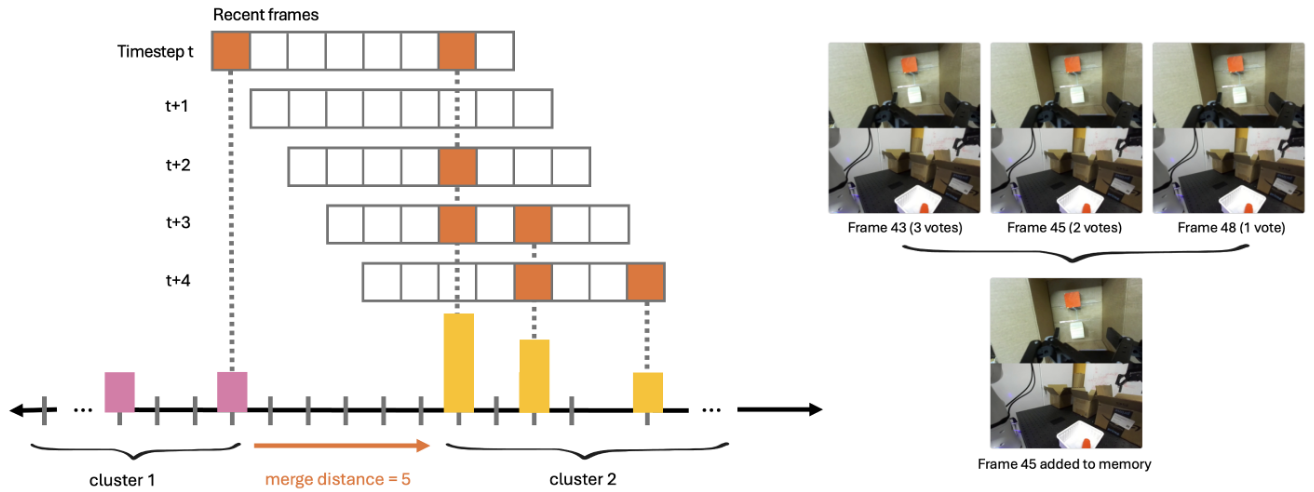
- 候选帧收集。高层政策在每个时间步都会从近期 8 帧中提名候选关键帧 Jₜ,系统收集所有时间步的候选帧,提取其时间索引并形成有序列表 G₀:ₜ。列表会保留重复索引 —— 例如某帧被多次提名,说明其包含的信息对任务至关重要。
- 聚类分组。系统将时间间隔不超过 d 帧(实验中 d=5)的索引归为同一聚类。例如索引 {1,3,3,4,10} 会被分为两个聚类:C₁={1,3,3,4}(间隔均≤5)、C₂={10}(与前一聚类间隔 6>5)。这种分组方式确保同一聚类的帧代表同一关键事件(如 “查看左侧箱子” 的整个过程)。
- 代表帧选择。对每个聚类,选取中位数索引对应的帧作为最终关键帧。例如聚类 C₁的中位数索引为 3,对应的帧即为该事件的 “记忆锚点”。这种方式既减少了冗余(每个事件仅保留 1 帧),又能最大程度保留关键信息 —— 中位数索引能平衡事件的开始与结束阶段,避免遗漏重要细节。
通过该机制,MemER 能将整个任务周期的数千帧图像浓缩为不超过 8 帧的关键帧集合,在降低计算成本的同时,确保了记忆内容与任务强相关。
为降低实际应用门槛,MemER 在训练与部署层面做了几项关键优化:
小数据高效训练:不同于传统长时序任务需要海量标注数据,MemER 仅需两类数据就能完成微调:一是 50 条完整的长时序任务演示轨迹(每条包含图像、本体感受数据、子任务标注),二是 10-15 条干预演示(用于处理部署中的常见失败场景,如夹爪未抓稳物体)。这种小数据需求源于高层政策复用了 Qwen2.5-VL-7B-Instruct 的预训练视频理解能力即在微调过程中冻结视觉编码器和投影层的权重。低层政策则复用了 π₀.₅在DROID 数据集上的控制能力。
模型融合策略:高层政策微调后可能会丢失预训练模型的鲁棒性(如对异常帧的容忍度)。研究团队**采用 “权重插值” 方案:将微调后的模型权重 θ_ft 与预训练权重 θ_pre 按 α=0.8 的比例融合(θ_final = 0.8×θ_pre + 0.2×θ_ft)。**实验显示,该策略能在保持任务适配性的同时,提升模型对低层政策重试、冻结等异常情况的容忍度,三项任务的平均性能提升约 5%。
异步闭环部署:为平衡推理质量与响应速度,MemER 采用异步调度。高层政策以 1Hz 频率更新子任务与关键帧,低层政策以 2Hz 频率输出动作。系统将图像以 2Hz 采样存入队列,高层政策完成当前推理后,直接从队列读取最新数据生成下一个子任务。这种方式避免了低层政策等待高层推理的延迟,确保闭环控制的稳定性。
4.Takeaways:
研究团队测试了两种文本记忆方案:
- 短历史 + 文本:高层政策使用最近 8 帧图像 + 对应的子任务文本描述;
- MemER + 文本:在 MemER 的关键帧基础上,添加对应的子任务文本描述。
实验结果显示,纯视觉记忆的 MemER 表现最优,文本记忆的加入反而导致性能下降。
这一结果证明,在机器人操纵任务中,视觉信息比文本描述更能精准传递记忆所需的空间细节与状态信息。
通用 VLM 是否能直接用于机器人记忆管理”。
实验发现,专有 VLM 存在两大致命问题:
- 延迟超标:专有 VLM 的 API 调用延迟为 10-15 秒,远超闭环控制的 1 秒容忍极限,直接部署会导致任务完全失败;
- 场景适配差:在离线实验中(使用预录轨迹,无实时延迟压力),GPT-5 的子任务预测准确率仅为 15%-43%,Gemini 的对应指标仅为 13%-23%,远低于 MemER 的 63%-87%。核心原因是专有 VLM 缺乏机器人场景适配,无法识别 “夹爪状态”“物体相对位置” 等关键感知线索,导致候选关键帧选择冗余、子任务指令与实际需求脱节。
结果显示,基于开源 VLM 进行针对性微调,比直接使用通用专有 VLM 更适合机器人长时序任务 —— 开源模型的可定制性,使其能更好地适配机器人特定的感知与决策需求。
局限性&未来工作:
- 缺乏过期记忆删除机制,仅能添加关键帧,若任务延长至数小时会导致关键帧集合膨胀、计算成本上升;
- 高层 1Hz、低层 2Hz 的调度频率,难以满足装配线分拣等高速操纵任务需求;
- 仅依赖视觉信息,未整合触觉、听觉等其他感官数据,记忆维度不够全面;
- 实验仅在单机械臂上完成,尚未适配移动操纵机器人或多机器人协作场景。
对应这些局限,未来需让高层政策学会判断记忆时效性以删除无用信息,通过优化模型缓存、改进 tokenization 算法提升控制频率,将多模态数据融入关键帧筛选以丰富记忆维度,同时探索空间映射与情景记忆结合的方案,适配更复杂的多机器人应用场景。
MemER | arxiv 2025.10.23 | Paper Reading