RMBench | arxiv 2026.03.01 | Paper Reading
RMBench: Memory-Dependent Robotic Manipulation Benchmark with Insights into Policy Design
这篇文章由RoboTwin团队提出,基于原先的RoboTwin平台,在此基础上引入了9个记忆相关的任务从而为具身智能在仿真记忆部分提供了一个比较友好的benchmark,对于我目前的研究方向提供了一个很好的训练评测平台。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | benchmark + memory complexity | benchmark memory eval policy | 2026-03-01 |
1.What?
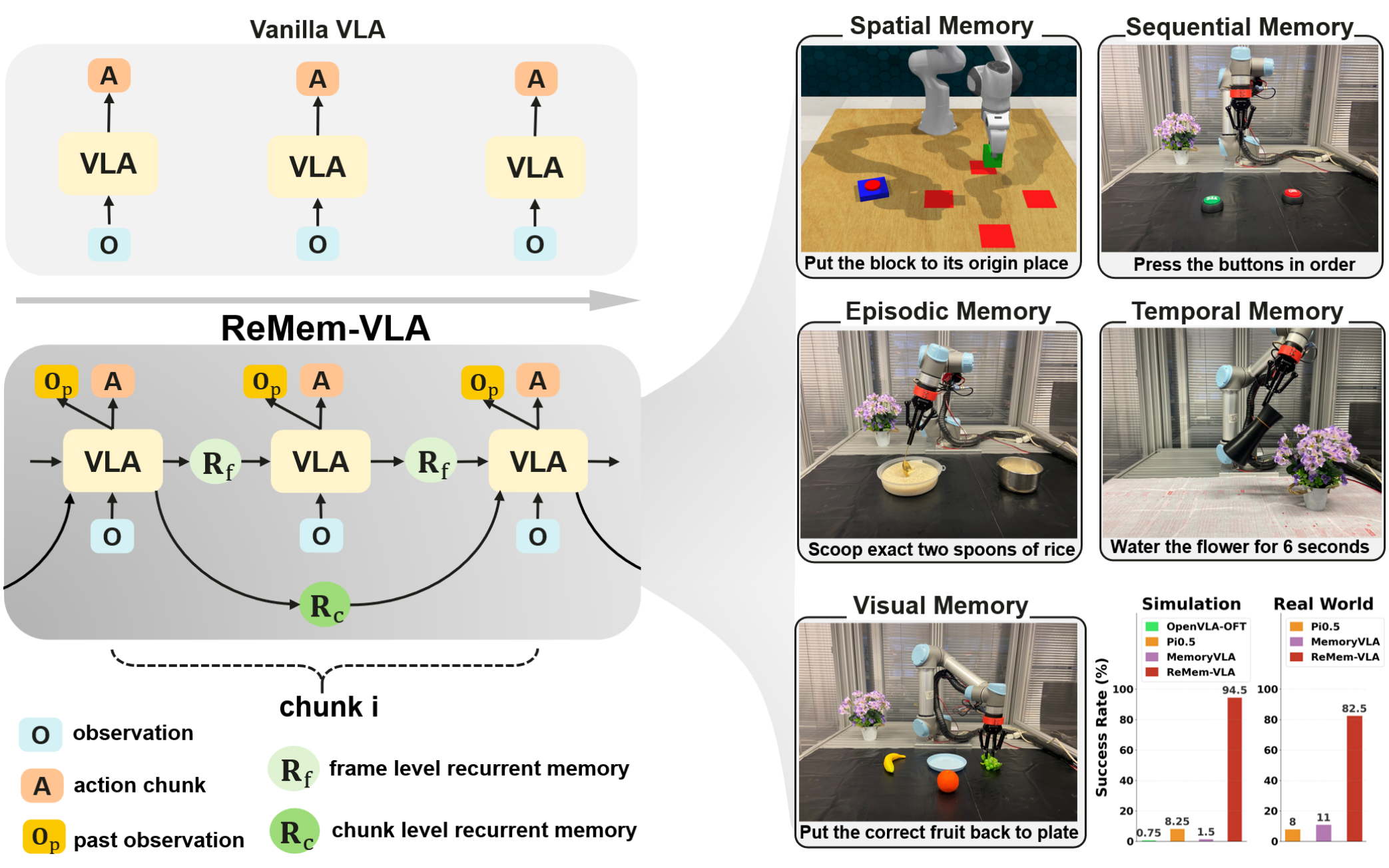
RMBench,一个包含9个作任务的模拟基准测试,涵盖多个内存复杂度层级,从而实现策略内存能力的系统评估。
Mem-0,这是一种模块化作策略,具有明确的记忆组件,旨在支持受控消融研究。
2.Why?
现有基准测试仅部分填补了这一空白。MemoryBench(Fang 等人,2025)包含七项涉及记忆的单臂操作任务,但其中仅有三项可在仿真中可靠复现,且该基准未能为原则性任务设计提供充分指导。MIKASA(Cherepanov 等人,2025)提出了32项记忆相关操作任务,但其构建方式主要适配强化学习而非通用模仿学习。LIBERO-Long(Liu 等人,2023)提供了十项长视域任务,然而这些任务并未明确要求记忆能力,因为所有任务相关信息在执行过程中始终可被观测。
为突破这些局限,我们首先提出任务记忆复杂度——一种用于量化机器人操作任务中记忆需求的原则性指标。该指标为分类记忆依赖型任务提供了系统化方法,并可作为任务设计的指导原则。基于此框架,我们提出基于 RoboTwin 2.0 平台构建的机器人操作基准测试 RMBench。RMBench 包含9项涵盖不同任务记忆复杂度层级的双臂操作任务,涵盖多个内存复杂度层级,支持对机器人操作中记忆保持与利用的大规模可控研究。
进一步地,我们提出 Mem-0——一种采用模块化组件设计的新型记忆导向机器人策略,其组件可便捷替换或重构。Mem-0 采用双系统架构,通过任务阶段分类器显式区分任务的不同阶段,实现长视域下的结构化记忆运用。通过对 Mem-0 进行系统化消融研究,我们分析了哪些设计组件对机器人操作中的有效记忆至关重要,并为未来策略设计提供了洞见。
3.How?
RMBench
3.1 任务记忆复杂度(TMC)
机器人操作常在部分可观测性下进行,仅凭当前观测往往不足以确定任务进度或正确的下一步动作,必须借助历史信息。这种部分可观测性可能源于遮挡、延迟效应或状态混叠。关键的是,所需的历史信息并不一定对应连续的最远观测序列,而可能是一组在任意时间步出现的、与任务相关的小规模观测集合。现有基准测试通常通过特定策略架构评估记忆能力,但缺乏一种以任务为中心的标准,用以刻画必须随时间保留多少任务相关信息。为填补这一空白,我们提出了任务记忆复杂度(TMC),它度量了为实现最优决策所需保留的最小历史信息量。
设定。我们将操作任务建模为一个部分可观测马尔可夫决策过程(POMDP),其中包含潜在状态 st ∈ S、观测 ot ∈ O 和动作 at ∈ A。令截至时间 t 的完整交互历史为 ht = (o1:t, a1:t−1)。(1)
我们并不假设能访问完整历史,而是考虑一个记忆状态,用于汇总来自过去观测的任务相关信息。令 Mt 表示基于 ht 构建的记忆表示,令 M(k) t 表示一个最多编码 k 个任务相关过去观测的记忆状态。
定义。任务记忆复杂度定义为满足以下条件的最小整数 m ≥ 0:存在一个最优策略 π∗,其在时间 t 的动作仅依赖于记忆状态 M(m) t。形式化表述为:
∃ π∗ s.t. π∗(at | ht) = π∗(at | M(m) t ), ∀t。(2)
任务标注。任务根据其任务记忆复杂度进行标注,使用记号 M(0)、M(1) 或更一般地 M(n),其中索引表示为最优解决任务必须保留的任务相关过去观测的数量。
解释。M(0) 表示无记忆任务,仅凭当前观测便足以唯一确定任务进度和最优动作。M(1) 表示需要保留单个任务相关过去观测以消除当前状态歧义的任务。更一般地,M(n) 表示其最优决策依赖于保留 n 个任务相关过去观测的任务,这捕捉了非局部和多步的时间依赖性。
3.2 RMBench 系统设计
RMBench 在 RoboTwin 2.0(Chen 等人,2025a)系统框架内开发。它基于 SAPIEN(Xiang 等人,2020)仿真引擎构建,并在统一流程中支持自动化数据合成与集成策略评估。此设计实现了可扩展的数据生成以及机器人操作策略的一致且可复现的基准测试。
此外,我们提供了与每个动作-观测对对齐的细粒度语言标注。这些标注为底层交互和状态转换分配了明确的语言描述,为下游训练高级推理或记忆模块提供了结构化和密集的监督信号。
3.3 RMBench 基准测试任务
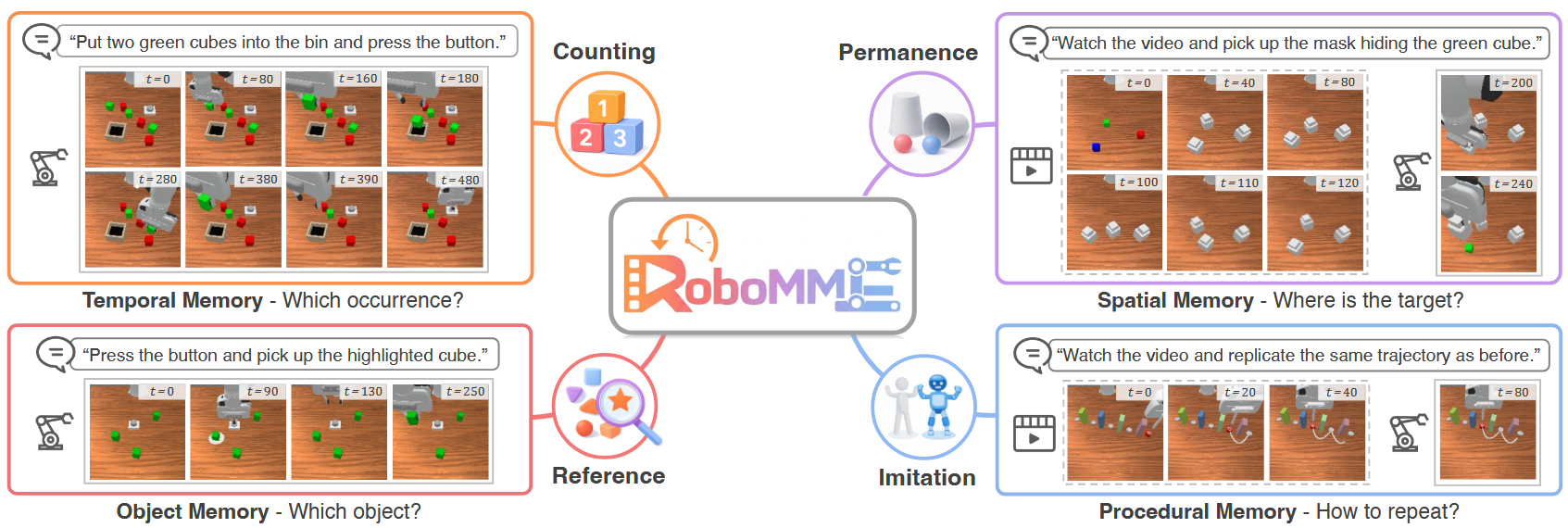
基于提出的任务记忆复杂度(第 3.1 节),我们共设计了九个依赖记忆的操作任务。这些任务分为两类:五个 M(1) 任务和四个 M(n) 任务。每个任务的代表性关键帧如图 1 所示,详细任务规格见附录 A。
M(1) 任务包括:观察并拾取、重排积木、放回积木、交换积木和交换 T 形块。这些任务要求策略保留单个过去观测或固定、有限数量的历史帧。成功执行依赖于在任务不同阶段动态关注任务相关信息。
M(n) 任务包括:**积木排序尝试、按下按钮、覆盖积木和电池尝试。**这些任务需要重复的主动探索、试错交互,或针对任务特定尝试次数进行重复执行,且通常由外部反馈引导。因此,它们要求强大的长期记忆保留和有效检索机制,以便在较长时域内积累和利用历史信息。
Mem-0
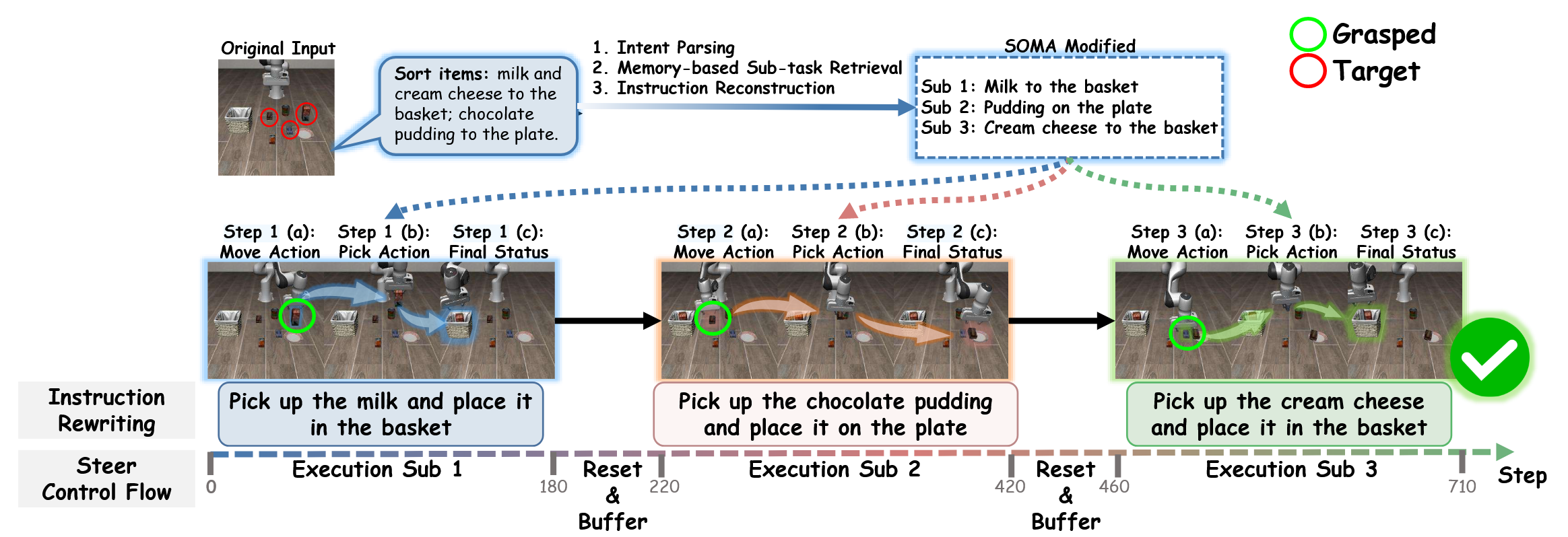
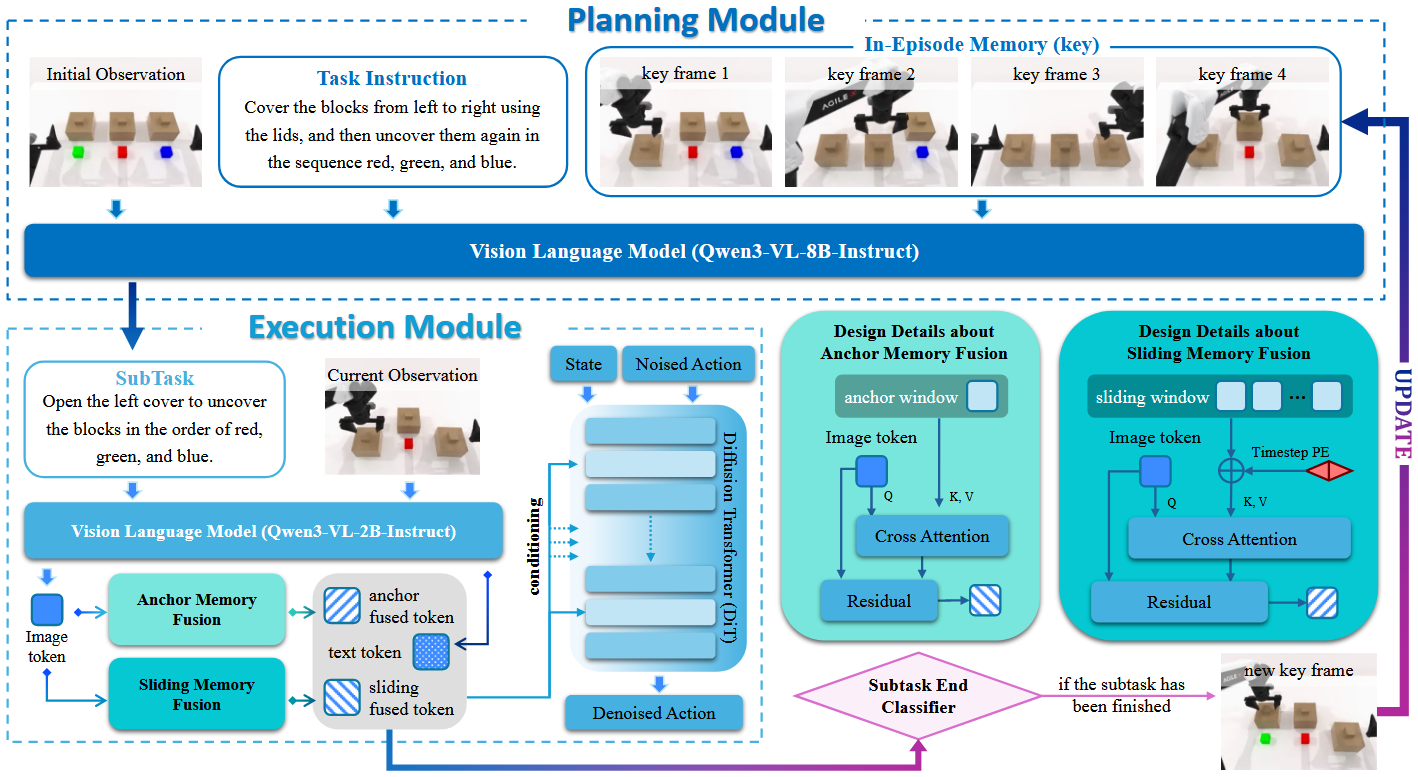
Mem-0 由规划模块和执行模块组成,并通过子任务终端分类器相连。规划模块从任务指令、观察和关键帧内存生成高级子任务,而执行模块则利用当前观察、子任务以及融合锚点和滑动记忆,在基于扩散的策略中生成低级别动作。子任务完成后,会存储一个关键帧,以便迭代规划和执行直到任务完成。
4.Takeaways:
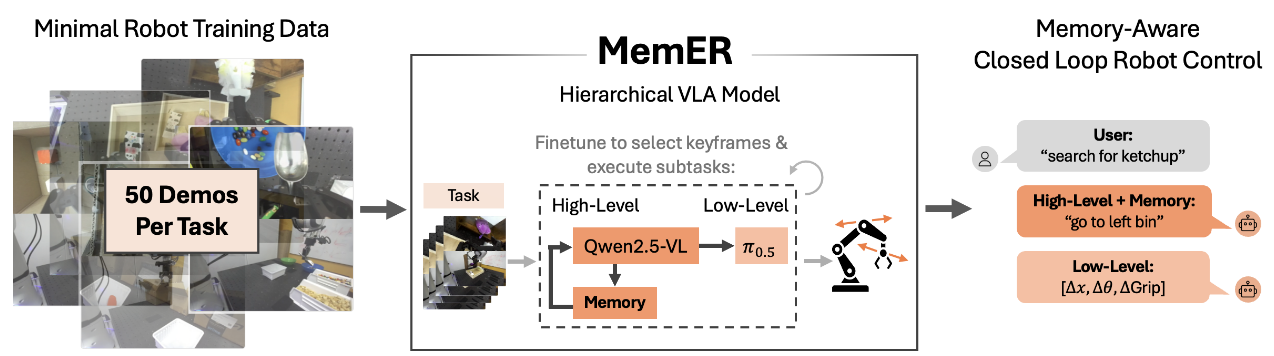
论文特别提到,设计不当的记忆可能通过因果混淆损害模仿学习:记忆会强化一些与真实因果无关的虚假相关,反而干扰策略。MEM通过多尺度、多模态的设计(短期用压缩视频、长期用抽象语言),并让模型主动选择记什么,有助于把记忆用在“任务进度与状态”上,而不是堆砌容易造成混淆的原始观测,从而在“利用历史”和“保持策略清晰”之间取得平衡。
MEM VLA不仅在需要记忆的任务中能有效利用记忆,还能在挑战性灵巧操作任务中达到与π0.6 VLA相当的先进性能。这一点尤为值得关注,因为先前诸多研究指出为策略添加记忆常导致性能下降(例如因因果混淆问题[11, 54])。我们将MEM的强大性能主要归因于多样化的预训练数据混合,其中除包含多样的互联网视频外,还有不同最优性、速度与控制频率的机器人操作片段。这种多样性共同防止了视频编码器在训练较小、较单一的机器人数据集时可能产生的虚假关联,并防止先前工作中报告的具有记忆的策略的脆弱性和性能下降。
局限性&未来工作:
未来工作可以探索如何将记忆扩展至单次任务周期之外,覆盖数周、数月甚至数年的部署时长,从而构建能在部署期间持续学习的机器人系统。
RMBench | arxiv 2026.03.01 | Paper Reading