MEM | arxiv 2026.03.03 | Paper Reading
MEM: Multi-Scale Embodied Memory for Vision Language Action Models
这篇文章由PI团队提出,基于原先的
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | VLA + long short term memory | causal-temporal attention VIT long short term memory | 2026-03-03 |
1.What?
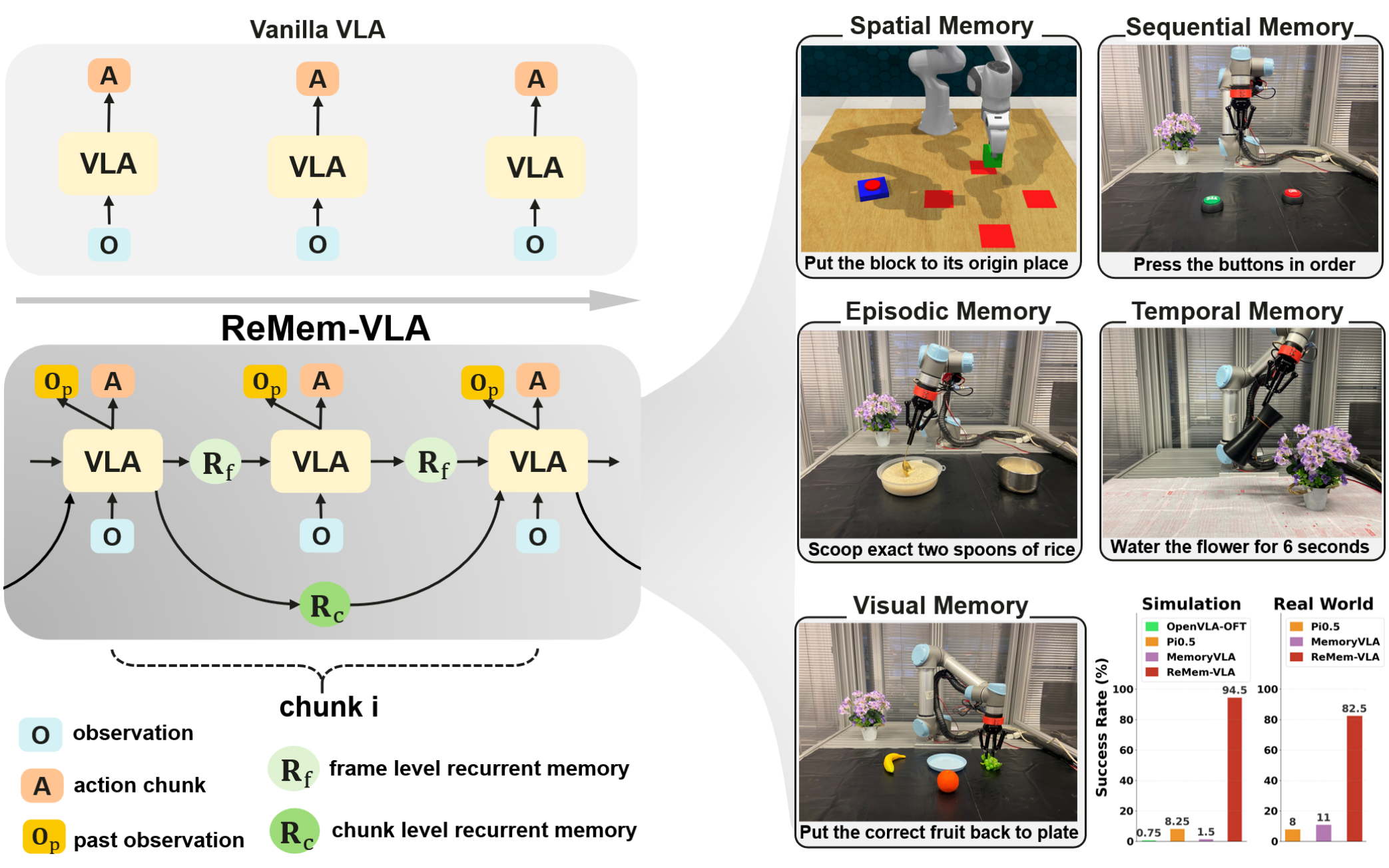
PI团队提出一种多模态记忆系统(VLA+RL+Long Short-term Memory),将短时程密集视觉记忆与长时程语言记忆相结合。该系统能解决部分可观测性问题,实现情境自适应,并完成长时程任务,同时保持高效性。
2.Why?
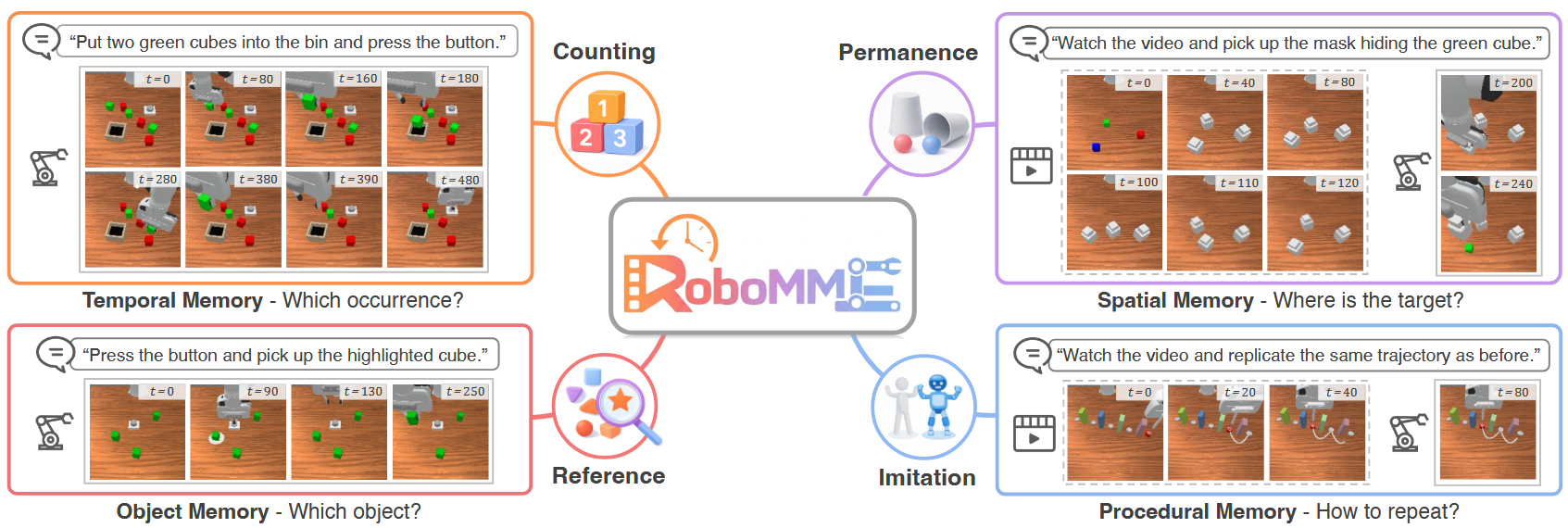
在复杂的多阶段现实世界任务中,机器人的记忆必须表征多个粒度层次的过去事件:从捕捉抽象语义概念的长期记忆(例如,正在烹饪晚餐的机器人应记住食谱的哪些步骤已完成),到捕捉近期事件并弥补遮挡的短期记忆(例如,机器人需记住当其机械臂遮挡目标物体时,仍能回忆起待拾取的物体)。
3.How?
这个多尺度指的是同一个任务中记忆时间的长短
-
短期:视频编码器保留几秒到十几秒的、经压缩的帧序列历史;
-
长期:自然语言概括几分钟甚至更久的任务进度与状态。
MEM提供了一种多模态记忆机制,短期记忆以原始观察的形式维持,长期记忆则以自然语言的抽象概念形式存储。该模型主动选择通过一种推理机制来选择记住什么以及如何记住,这种机制也被用来选择高层次子任务,有效地推理该做什么,以及要记住什么。
长期记忆:论文中类似思维链的推理过程,其中高层次子任务 (“拿起盘子”或“洗碗”)被选中频率较低, 而动作则根据最新的子任务以高频率选择。MEM将这一高级子任务推理过程扩展到还产生新的 文本记忆,作为未来推理步骤的输入。 模型随后可以训练以多种方式记住事件:此外 只需记录下被选中的具体子任务,模型就可以 总结过去的事件(例如,在“拾起绿板”之后“拾起黄盘”) 变成“我拿了车牌”),并动态选择正确的事件 在保持整体语境规模可控的同时,实现了代表性。
虽然原则上我们可以简单地将过去观察的整个序列编码到策略上下文中,但这对于长时任务会变得难以处理,必须采用极短的序列或大幅降采样。然而在实际场景中,长短期记忆所需的表征可能存在本质差异。例如,机器人可能需要记住近期观察以应对遮挡,也可能需要记住烹饪时已添加某一种食材。但这两类记忆存在根本区别:前者可能只需短期存储少量图像,后者则需要长期记忆但仅涉及少量信息比特。有效的机器人策略记忆架构应当采用多模态来表征这些不同抽象层级的记忆。
对于短期记忆,基于图像的密集记忆非常适合解决遮挡问题,使机器人能快速调整操作策略(例如抓取失败后改变抓取方式)。对于长期记忆,我们通常只需在语义层面追踪事件,比如某食材是否已加入菜肴。此时基于语言的表征比原始观察数据具有更好的压缩性,使我们能够长期存储高层次记忆。
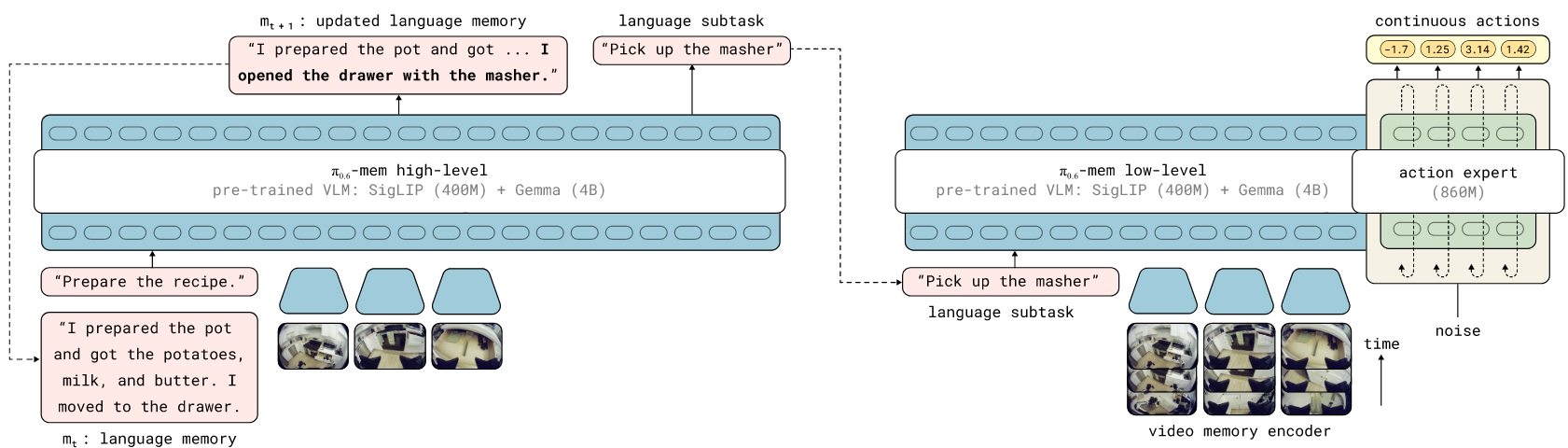
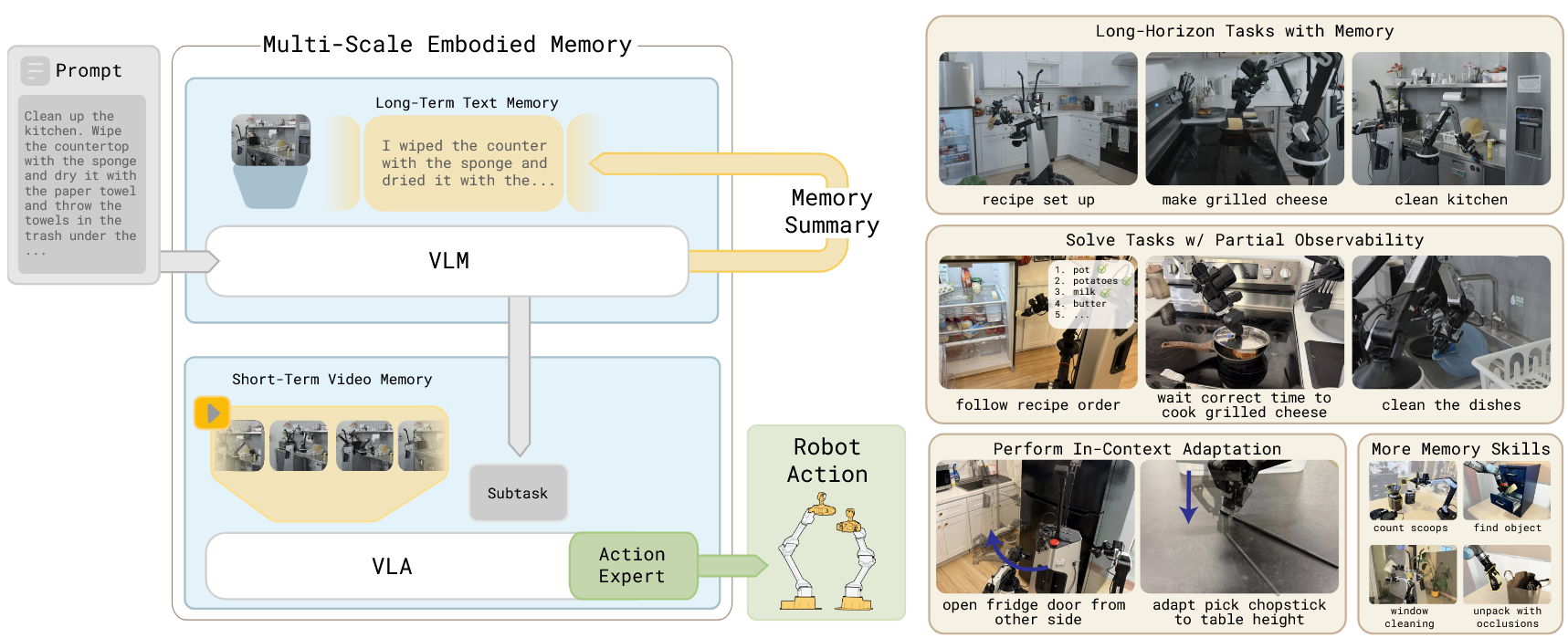
图2展示了MEM系统的整体架构。我们的目标是训练策略π(at:t+H |ot−T :t, g),使其能根据自然语言描述的任务目标g及输入的密集观测序列(如图像、本体感知状态),预测连续机器人动作段at:t+H。相较仅以单次观测ot为条件的传统视觉语言动作模型,本系统要求策略处理大量(T个)历史观测。如前所述,若要将历史观测扩展至分钟级以形成长程记忆,直接扩展观测数量并不可行。因此我们将动作预测问题分解为:
该式将动作概率分解为底层策略πLL与高层策略πHL:底层策略根据任务目标g、短观测序列(K≪T)及子任务指令lt+1建模动作序列;子任务指令则由高层策略生成,该策略不仅以任务目标为条件,同时结合自然语言描述的历史语义事件摘要mt(下文称为语言记忆)。这种设计在保持数分钟级记忆能力的同时,显著减少了输入模型的密集观测数量(K≪T)。尽管已有研究采用类似的高层-底层策略架构并以子任务指令作为接口,本系统的核心创新在于πHL能基于其先前预测的记忆状态mt,自主生成更新的语言记忆mt+1。
B. 语言记忆用于长期存储
语言记忆
C. 用于密集短期视觉记忆的视频编码器
如上一节所述,语言记忆机制能够捕捉长期语义概念。为使我们的策略能够推理细粒度细节、动态变化并解决自遮挡问题,需要将先前观测的密集序列 ot−K:t 作为输入提供给策略。在大多数视觉语言智能体(VLA)中,观察数据(尤其是图像)的编码过程占据了训练期间最大的计算开销,并显著影响推理速度。因此,如图3所示,当上下文长度超过数个时间步时,若仅简单地将一系列观察数据逐一编码并传入VLA骨干网络,很快就会变得不可行。对于灵巧操作任务,若要保持机器人性能不显著下降,VLA的推理延迟将迅速超过以往研究认为可接受的范围。为解决这一问题,我们提出采用视频编码器在时间维度上压缩帧序列,再将编码结果输入VLM骨干网络。我们的视频编码器扩展了视觉Transformer(ViT)——通常作为多数VLA的视觉编码器——以处理视频输入。重要的是,该编码器保持了初始VLM的单图像处理性能不变,因此可用于为任何预训练的VLM赋予高效(且计算成本低廉)的视觉记忆能力。ViT将图像分割为多个图块进行处理,并反复执行跨补丁嵌入(跨多层)的双向注意力机制,生成最终输出嵌入集合。我们保持总体架构不变,视频编码器首先对输入视频中的所有图像分别进行补丁化处理。受现有时空分离注意力在视频理解中的应用启发(综述可参考 Bertasius 等人 [3]),我们随后在 ViT 每第 4 层修改注意力机制,使其同时融合空间(ViT 标准方式)与时间上下文。为避免在时空总补丁数极大时进行代价过高的联合注意力运算,本架构将注意力分解为独立的空间与时间注意力操作。每第 4 层通过因果注意力掩码("时间"注意力)对同一图像补丁在各时间步的表征执行时间维度上的注意力叠加——可视化示意图见图 4,数学描述见附录 C。这将每层对应注意力的计算复杂度从 O(n²K²)(时空联合朴素注意力)降低至 O(Kn² + nK²)。最后,为减少后续 VLA Transformer 骨干网络处理的补丁数量,我们仅传递当前时间步计算得到的表征(舍弃过往时间步的所有补丁表征)。因此,本视频编码器输出的令牌数量与单时间步无记忆 VLA 中传入骨干网络的典型令牌数保持一致;我们通过改进的注意力机制,有效迫使视频编码器将时序信息整合到当前观测生成的表征中。
本视频编码器的关键特性在于:相较于标准单图像 ViT,其未引入新的可学习参数。视频编码能力通过修改 ViT 的注意力模式并添加固定的正弦时间位置编码实现。因此,我们可以像无记忆 VLA 那样,从任何标准视觉语言模型的预训练 ViT 权重初始化视频编码器权重。为最大化特征迁移效果,我们确保当 K = 1(即单图像输入)时,编码器初始化状态与 VLM 完全一致——这是通过令 t = 0 时正弦时间位置编码值为 0 实现的。
D. 将 MEM 集成至 π0.6 VLA
在实验评估中,我们通过调整 π0.6 VLA [35] 的架构以支持第 III-C 节的视频编码器,为其配备 MEM 记忆。与 π0.6 相同,搭载 MEM 的 π0.6 VLA 从预训练的 Gemma3-4B VLM [21] 初始化。遵循 Driess 等人 的方法,模型通过离散 FAST 动作令牌预测 [33] 和含 8.6 亿参数的流匹配动作专家 [18] 进行联合训练,且梯度不从动作专家回传至 VLM 骨干网络 [16]。模型训练时每路相机流输入分辨率为 448×448 像素,最多支持四路相机流(取决于机器人实体)。除历史相机帧外,配备 MEM 记忆的 π0.6 模型的观测记忆还包含历史本体感知状态(如关节角度)。π0.6 VLA 以文本形式表示机器人状态,但对于连续历史状态序列,这会导致状态文本令牌数急剧增长。为此,我们改用连续状态嵌入方式:通过线性投影将每个本体感知状态映射至骨干网络嵌入空间。这样,对于长度为 K 的观测记忆,我们仅生成 K 个本体感知状态令牌。
我们参照 Physical Intelligence 等人的方法,在包含遥操作机器人示教、策略运行数据、人工校正数据、视觉语言任务及视频语言任务(如视频描述)的多样化混合数据上对 π0.6-MEM 进行预训练。预训练阶段,模型使用间隔 1 秒的六帧观测序列(五帧历史观测加当前观测)进行训练。在后训练阶段,我们发现可灵活扩展此时序范围,支持更长的基于观测的记忆(实验中最多达 18 帧、54 秒),这与语言模型和视觉语言模型训练中的观察结果一致 [10]。所有机器人实验均采用推理时实时分块(RTC, [6])或训练时 RTC [7] 技术实现异步实时推理。
4.Takeaways:
论文特别提到,设计不当的记忆可能通过因果混淆损害模仿学习:记忆会强化一些与真实因果无关的虚假相关,反而干扰策略。MEM通过多尺度、多模态的设计(短期用压缩视频、长期用抽象语言),并让模型主动选择记什么,有助于把记忆用在“任务进度与状态”上,而不是堆砌容易造成混淆的原始观测,从而在“利用历史”和“保持策略清晰”之间取得平衡。
MEM VLA不仅在需要记忆的任务中能有效利用记忆,还能在挑战性灵巧操作任务中达到与π0.6 VLA相当的先进性能。这一点尤为值得关注,因为先前诸多研究指出为策略添加记忆常导致性能下降(例如因果混淆问题)。我们将MEM的强大性能主要归因于多样化的预训练数据混合,其中除包含多样的互联网视频外,还有不同最优性、速度与控制频率的机器人操作片段。这种多样性共同防止了视频编码器在训练较小、较单一的机器人数据集时可能产生的虚假关联,并防止先前工作中报告的具有记忆的策略的脆弱性和性能下降。
局限性&未来工作:
未来工作可以探索如何将记忆扩展至单次任务周期之外,覆盖数周、数月甚至数年的部署时长,从而构建能在部署期间持续学习的机器人系统。
MEM | arxiv 2026.03.03 | Paper Reading