VLA-Adapter | AAAI 2026(oral) | Paper Reading
VLA-ADAPTER: AN EFFECTIVE PARADIGM FOR TINY-SCALE VISION-LANGUAGE-ACTION MODEL
这篇文章通过设计了一个bridge Attenion block以及广泛的实验尝试验证了小模型也能够有很好的性能。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | adapter | bridge Attention | 2025-10-07 |
1.What?
为了解决如何有效衔接视觉-语言表征与动作空间这一问题,提出VLA-Adapter这一创新范式,旨在降低VLA模型对大规模VLM和大量预训练的依赖。
首先系统分析了不同VL条件的有效性,并揭示了哪些条件对衔接感知与动作空间至关重要的关键发现。基于这些洞见,我们设计出带有桥接注意力机制的轻量化策略模块,可自主将最优条件注入动作空间。VLA-Adapter将充足的多模态信息传递至所提策略网络以生成动作,有效弥合了从视觉语言到动作的模态鸿沟。
该方法仅需0.5B参数的主干网络即可实现高性能,且无需任何机器人数据预训练。在仿真与真实机器人基准测试上的大量实验表明,VLA-Adapter不仅达到最先进性能水平,还实现了目前报道中最快的推理速度。得益于提出的先进桥接范式,VLA-Adapter仅需在单张消费级GPU上训练8小时即可构建强大VLA模型,大幅降低了VLA模型的部署门槛。
2.Why?
(i)SFT扩展所需的大规模人工示教轨迹数据稀缺且成本高昂;
(ii)对存在分布偏移任务的泛化能力有限。
面对高维控制环境时,VLA模型仍存在多重瓶颈:依赖大规模视觉语言模型、微调速度缓慢、GPU显存消耗高以及推理效率(吞吐量)低下
大规模具身数据集进行预训练将VLM与专用策略网络相结合,使系统能够以端到端方式解析或生成多样化任务的动作序列。此外,双系统VLA架构近期受到关注,这类方法通常引入中间潜在标记连接VLM与策略网络,通过异步机制增强双系统协同,从而缓解动作生成过程中的延迟问题。因此,如何高效衔接视觉语言感知空间与动作空间已成为VLA模型设计的核心挑战。
3.How?
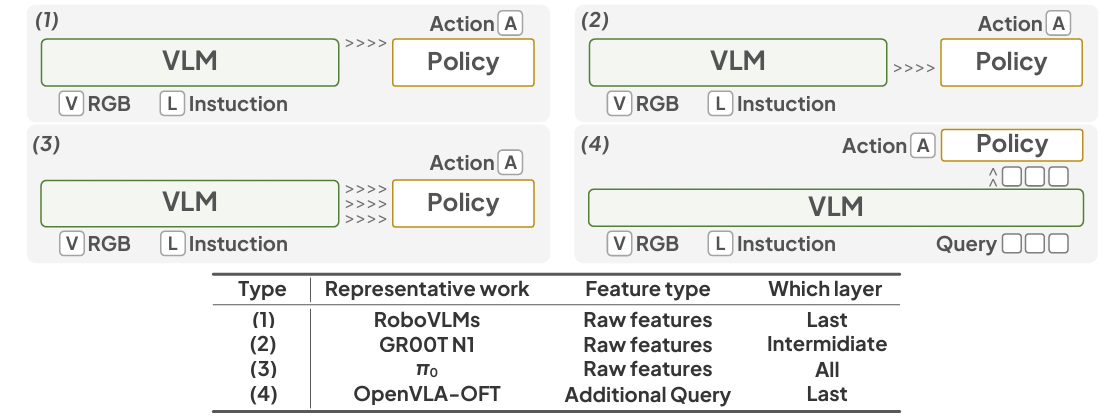
该视觉语言模型遵循PrismaticVLMs架构,包含M个网络层。在时间步t时,输入VLM的数据包含
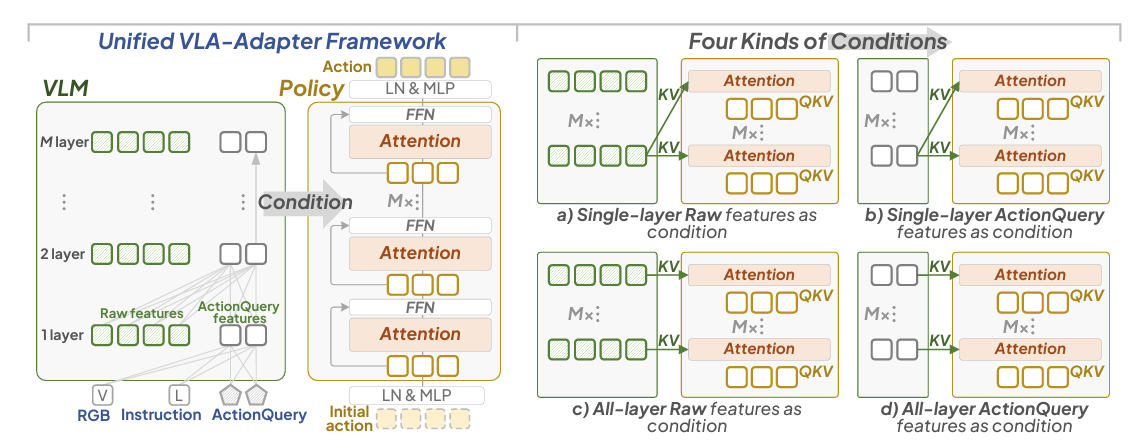
在第t个时间步,策略网络的输入包括:
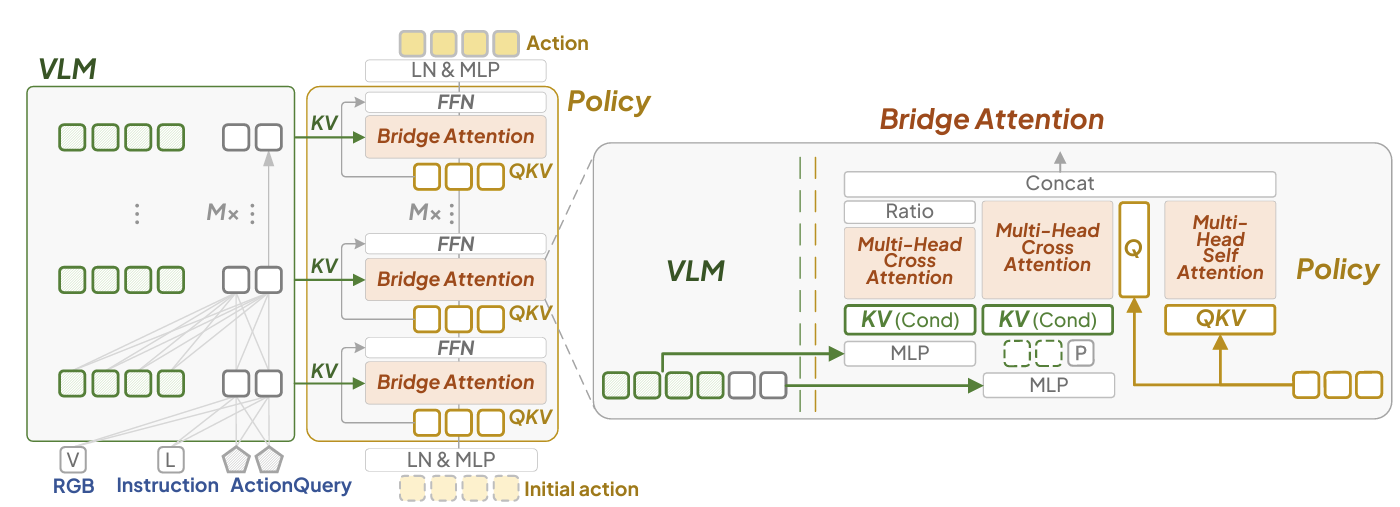
桥注意力机制。提出的桥注意力旨在通过条件
4.Takeaways:
关键发现1:
在
关键发现2:
对于
关键发现3:
多层特征组合性能更优。我们观察到使用全层级特征通常优于单层特征,不仅提升性能,还能节省设计过程中的最佳层级选择时间。这种设计更具普适性。
条件判定。
VLA-Adapter是否完全依赖
结论一:
当视觉语言模型未经过机器人预训练时,VLA-Adapter的改进效果显著。
结论二:
即使主干网络参数冻结,VLA-Adapter仍能保持强劲性能。
VLA-Adapter无需机器人预训练即可实现视觉语言模型的高效微调,其性能超越采用微型主干网络的基线方法
局限性&未来工作:
1.经过大量具身数据预训练且模型规模微小,其在现实系统中的泛化能力有待提升
2.策略网络生成动作的质量取决于视觉语言模型提供的条件及其利用方式->深入探索这些条件以改进其表征能力并确保高效利用
3.VLA-Adapter的基础训练流程仍相对简单->可探索强化学习等复杂训练流程
VLA-Adapter | AAAI 2026(oral) | Paper Reading