SimpleVLA | arxiv 2025.9.11 | Paper Reading
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
这篇文章通过对GRPO改进为DAPO之后引入VLA达到很好的性能。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | RL | DAPO | 2025-10-07 |
1.What?
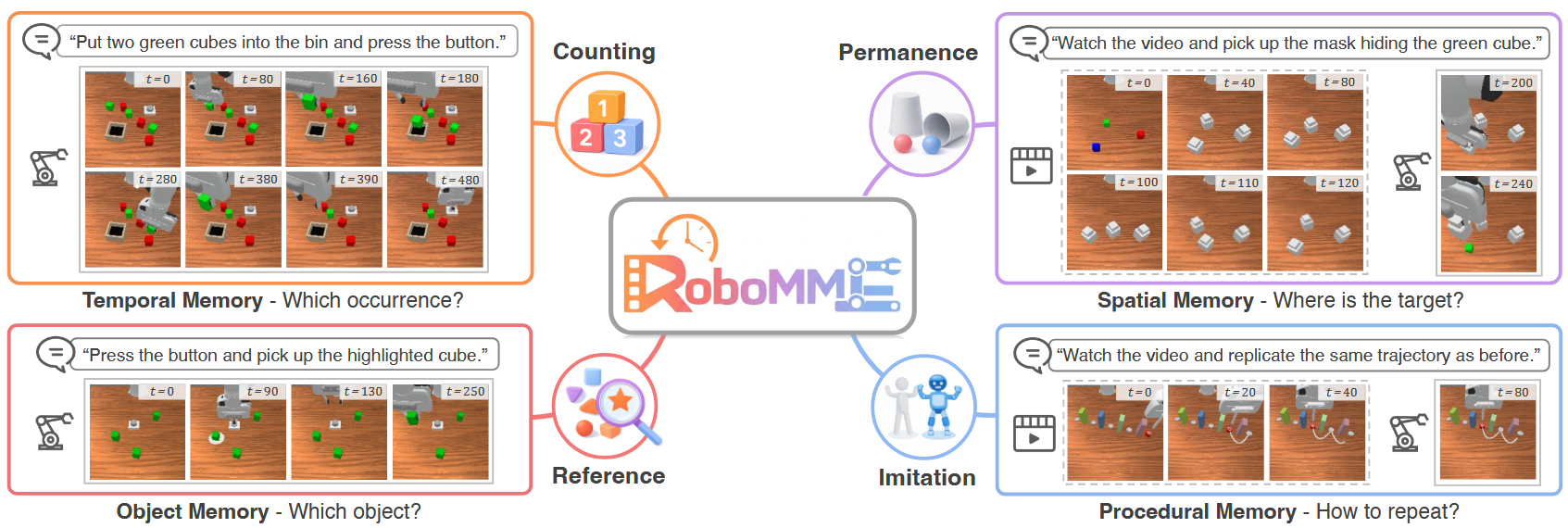
SimpleVLA-RL:一个专为VLA模型设计的高效RL框架
2.Why?
(i)SFT扩展所需的大规模人工示教轨迹数据稀缺且成本高昂;
(ii)对存在分布偏移任务的泛化能力有限。
3.How?
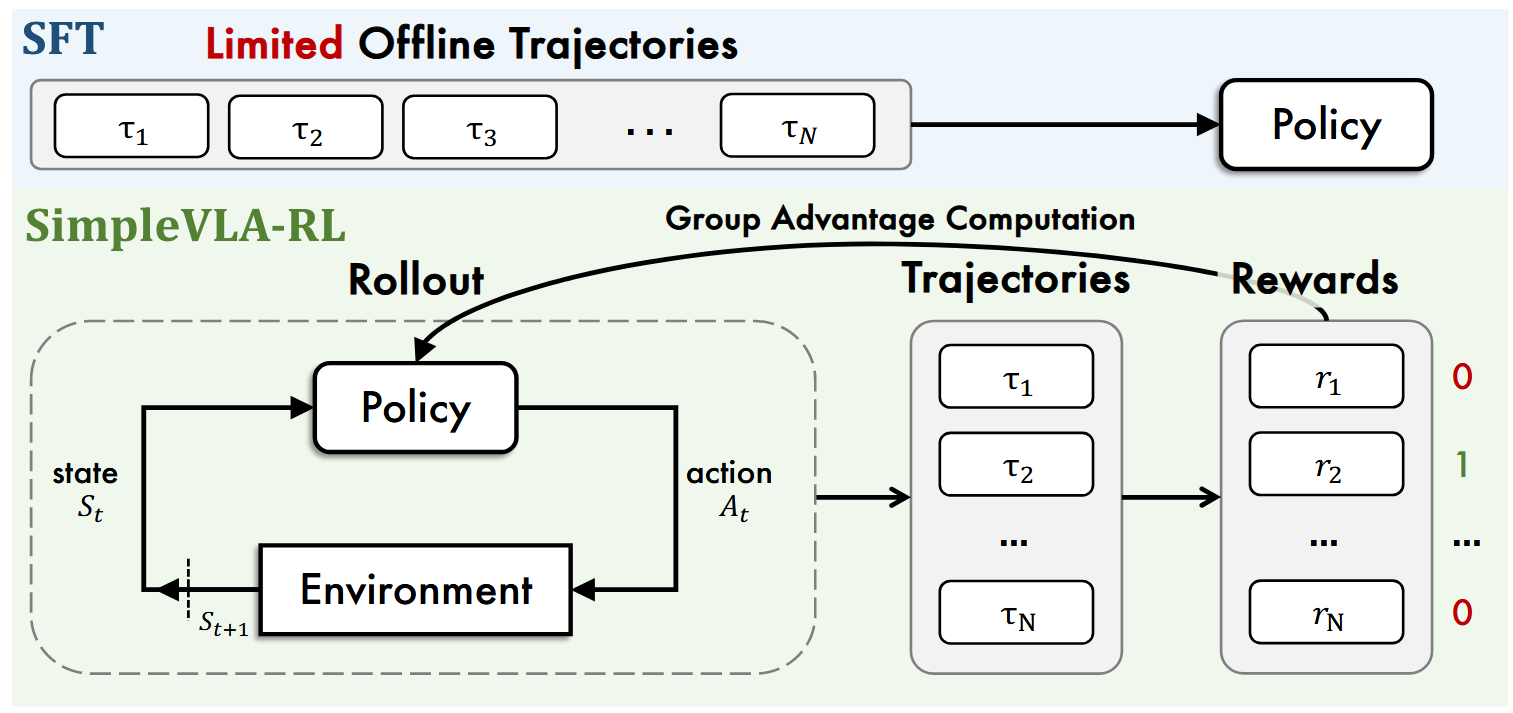
基于veRL,我们引入了VLA专用的轨迹采样、可扩展并行化、多环境渲染及优化损失计算
首重要价值。
受DeepseekR1启发将R1这类在线RL引入VLA仅需单调演示轨迹+0/1奖励信号即可实现高成功率
算法流程:
Step1: VLA模型与环境交互采样出多条不同轨迹
Step2: 根据环境反馈的任务是否成功的信息为每条轨迹赋予0/1的奖励值
Step3: 使用 GRPO等强化学习算法对模型进行On policy优化
对每个任务将仿真环境重复8次,将8个环境的state 0输入Policy model 中通过温度采样让policy model针对相同的state 输出不同的action。之后8个环境依次执行8个action更新得到的新的8个state 1.依次类推直到任务完成或者达到最大的Token上限。
由上述过程得到了多条轨迹。同时针对每条轨迹成功或失败也会有0/1表示(reward = 0/1)
将action和reward带入到GRPO中得到loss用于更新model
鼓励模型探索:
- Dynamic Sampling
- Clipping Higher
- Higher Rollout Temperature 提升温度1.0→1.6
4.Takeaways:
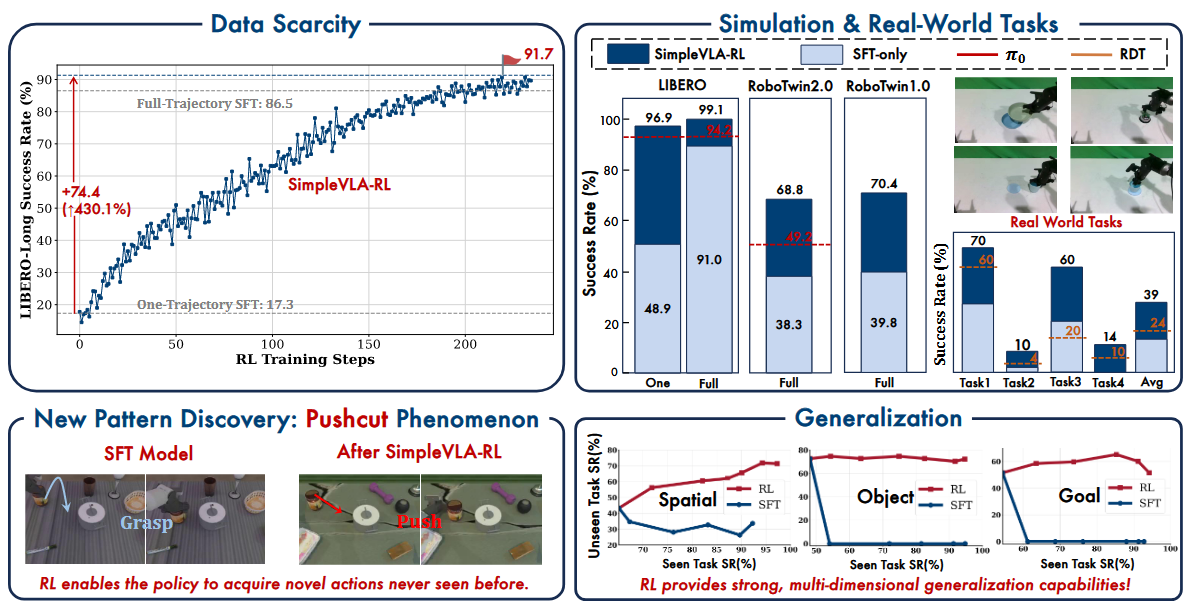
1.RL有好的泛化性在其他任务上学习在未见过任务上也能有很好的效果
2.基础模型决定了模型的效果,基础模型越强加入RL后效果越好
3.在加入RL前基础模型首先要有一定高度基础能力
4.如果只用0条轨迹训练则成功率为0即使加了RL也是0
Pushcut现象:(即策略能够自主发掘训练过程中未见的行为模式)
对于RoboTwin中的部分任务原本的逻辑在引入RL后会自动学到一些新的解决方式,只要满足定义即可。
eg. 模型抓住罐子移到锅旁边,现在可以将罐子或者锅推到另一个物体旁边
局限性&未来工作:
作者采用的这种0/1reward在长程任务上表现不好
SimpleVLA | arxiv 2025.9.11 | Paper Reading