SP-VLA | arxiv 2025.10.03 | Paper Reading
SP-VLA: A JOINT MODEL SCHEDULING AND TOKEN PRUNING APPROACH FOR VLA MODEL ACCELERATION
这篇文章通过现有双系统进行动态调整以及动态剪枝来达到减低参数同时提升模型精度。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | 双系统VLA | 双系统动态调整,动态剪枝 | 2025-11-02 |
1.What?
SP-VLA通过联合调度模型和修剪 token 来加速 VLA 模型
2.Why?
序列动作生成中的时间冗余和视觉输入中的空间冗余
3.How?
基于空间语义双重-觉察的 token 剪枝:
将 token 分为空间和语义两个类型,并根据其双重-觉察重要性进行剪枝
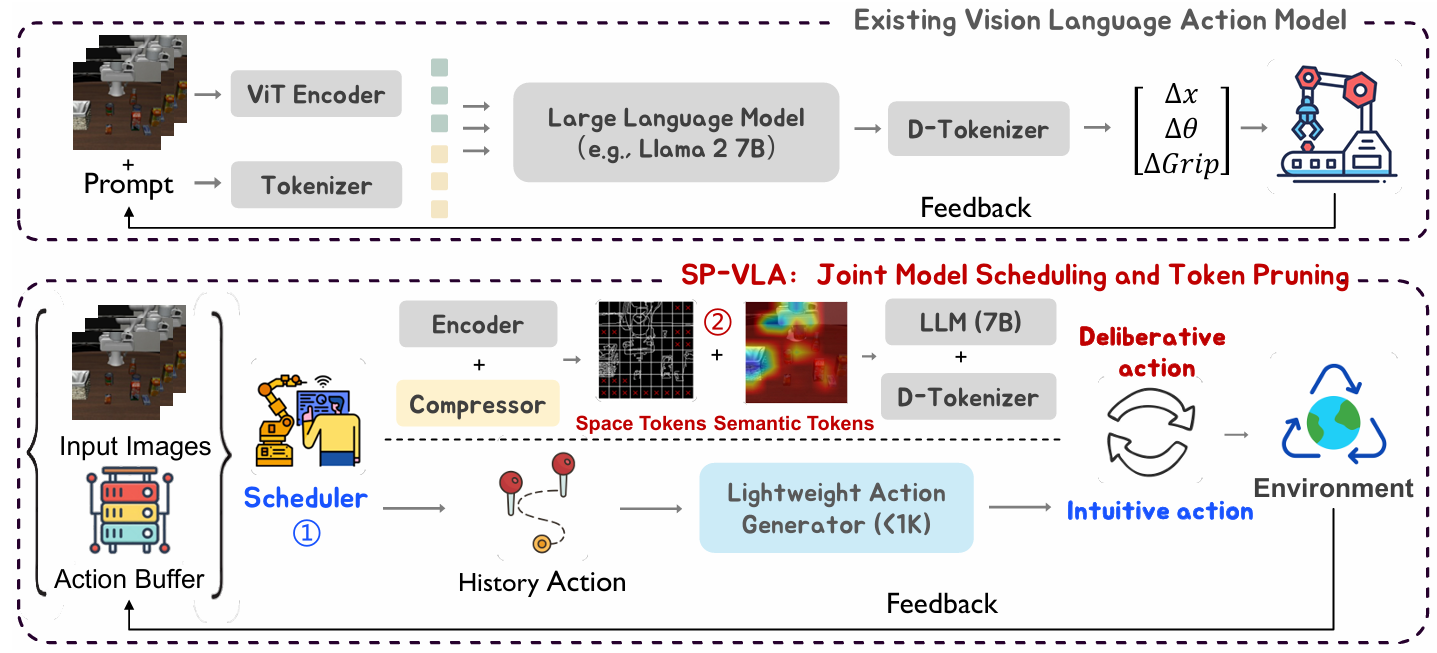
在处理环境反馈之前,会分析历史动作序列,以确定当前步骤需要的是深思熟虑的动作还是直觉动作。直觉动作由轻量级生成器生成,而深思熟虑的动作则由 VLA 处理。此外,在进入 LLM 主干网络之前,会根据输入 token 的空间上下文和语义重要性对其进行剪枝,从而进一步降低计算开销。
动作其实并不是同等重要,本文将 VLA 模型的动作输出视为每时间步长的位移,即速度。令 a_t_d = {a_x,a_y,a_z} 表示末端执行器在时间步 t 的平移速度分量。如果动作 a_in ∈ a ∈ { |a_i| > v_min, ∀i ∈ {x, y, z} 的所有分量都超过预定义阈值 v_min,则该动作被归类为直观动作;否则,该动作被归类为慎重动作。
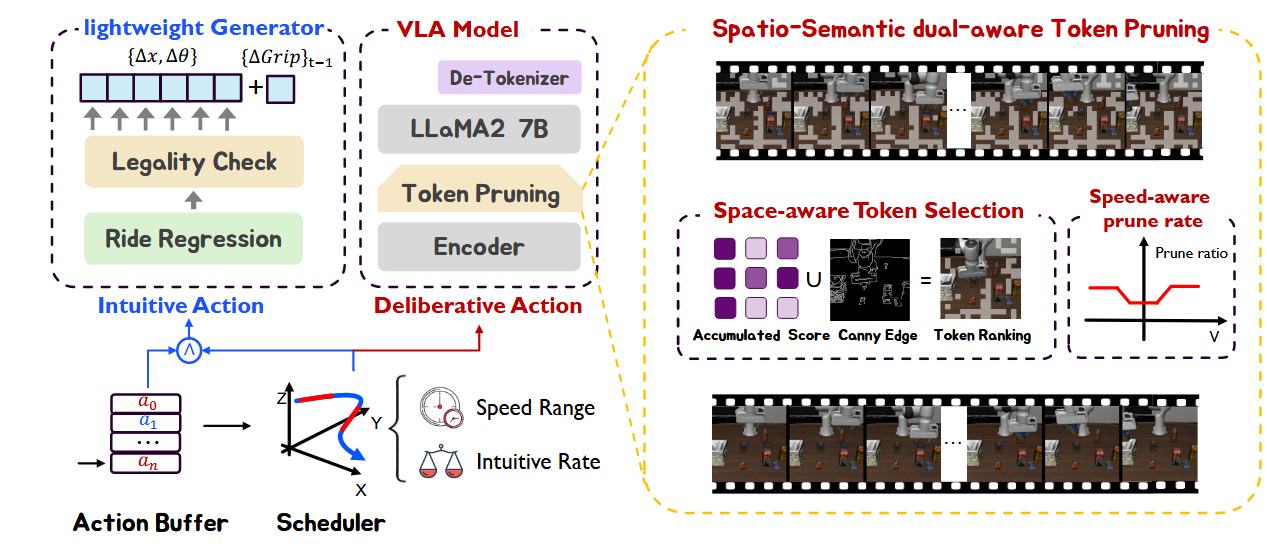
轻量级生成器,该生成器使用岭回归和动作缓冲区来高效地估计即将发生的动作。尽管机械臂的末端执行器轨迹很复杂,但假设直观动作的短片段可以近似为线性的。因此,通过在动作缓冲区中对时间和速度的关系进行建模,可以预测当前的动作。具体而言,动作缓冲区 S_A = {a_t−n, a_t−n+1, · · · , a_t−1} 用于存储最近 n 步生成的动作,t 是当前时间步,a_t = {a_1, a_2, · · · , a_l} 是 t 时刻的 l 维动作向量。T=[0,1,···,n−1]^T^ 是时间步长向量。岭回归模型的公式为 Y = Xβ + ε,其中 X = [T,1] 为输入,β 表示待拟合的参数矩阵,ε 为误差项,Y 为动作缓冲区。为了生成每个新动作,模型都会从头开始重新拟合,损失函数如下:J(β) = ||Xβ- Y|2 + λ||β|2
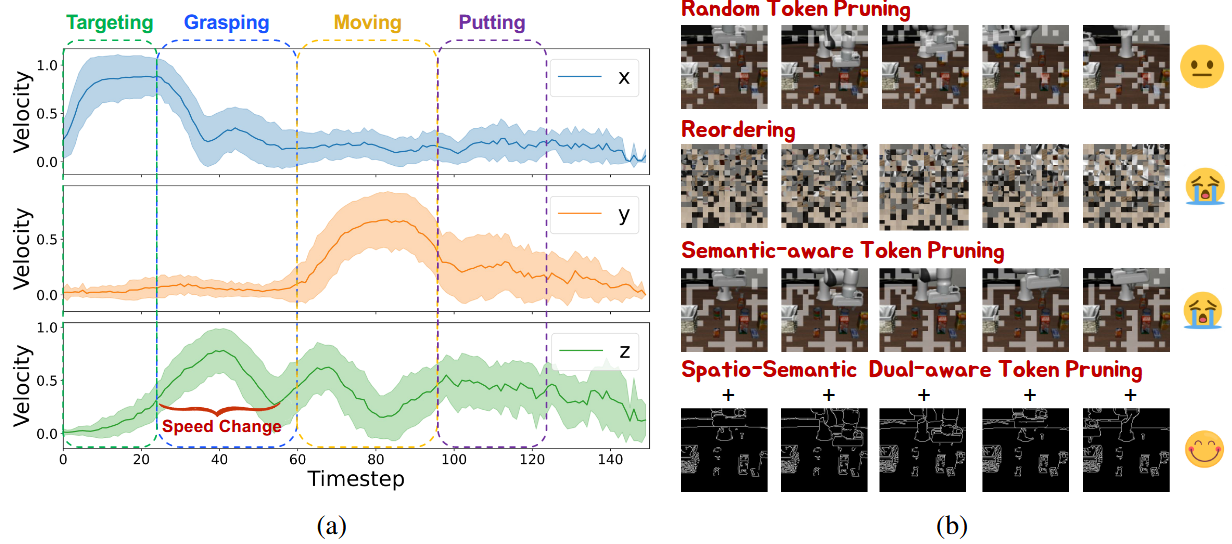
空间-觉察 token 重要性。假设空间信息主要编码在物体轮廓中。因此,使用 Canny 边缘检测器提取包含空间信息的 tokens。X_s = Canny(X) 表示仅保留从 X 提取的轮廓信息的纯边缘图像。然后,用 T_sp = f_E(X_s) 获得基于边缘 token 的有序序列,其中 f_E (·) 表示 token 提取函数。
最后,通过计算两者的保序并集 T_select = U(T_se,T_sp) 来获得选定的 token 集,其中 U(·) 表示保留原始 token 顺序的并集运算。
为了与模型协作策略保持一致,在低速条件下禁用 token 修剪,以避免干扰精确操作。此外,基于更高的运动速度通常对应更直观的操作,将修剪率定义为与当前速度正相关。因此,保留 token 的比例定义为:
4.Takeaways:
局限性&未来工作:
SP-VLA | arxiv 2025.10.03 | Paper Reading