RDP | RSS 2025 | Paper Reading
Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation
这篇文章通过软件与硬件两套设计实现了模型面对需要精细操作任务时的快速相应能力,其中的motivation很有意义。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | 快慢系统 | 双系统+力触觉的新思想 | 2025-10-04 |
1.What?
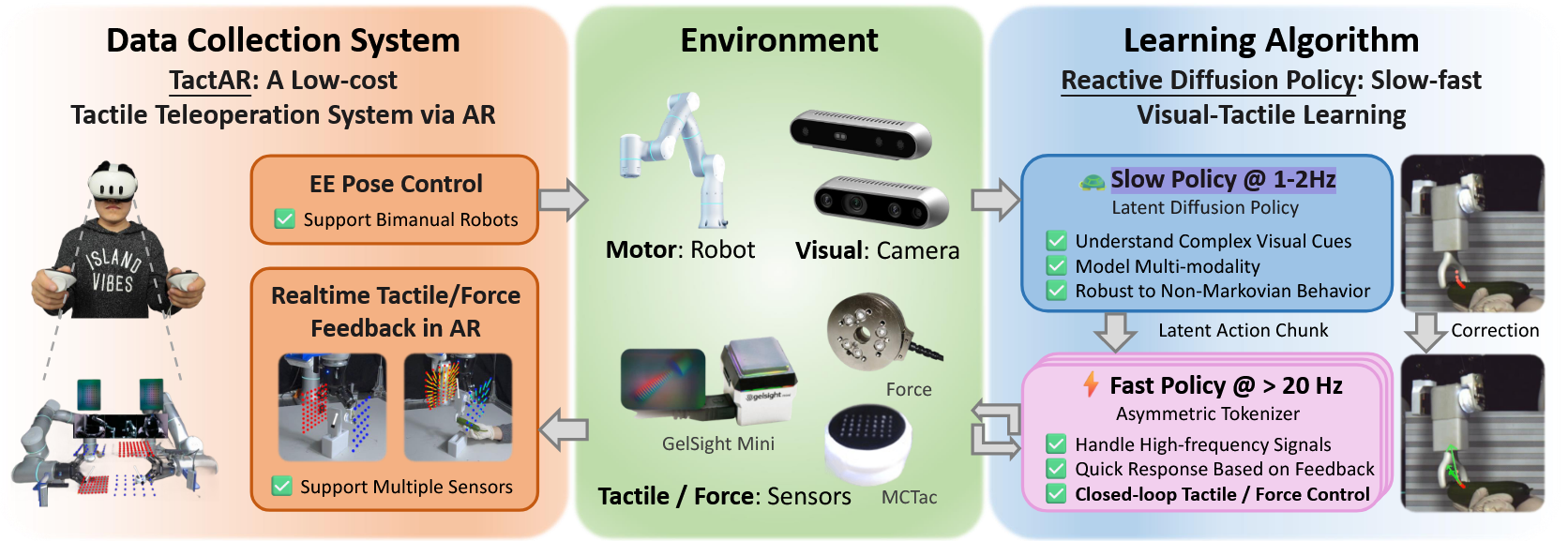
提出TactAR(一种通过增强现实提供实时触觉反馈的低成本遥操作系统)
Reactive Diffusion Policy(RDP,一种新型慢快视觉触觉模仿学习算法)
2.Why?
神经科学领域的一些研究成果表明,人类在执行接触密集型任务时,其过程可分为两个组成部分:1)前馈/预测性动作;2)基于感官反馈(如触觉信号)的闭环微调。受此启发,我们致力于开发一种能模拟人类在执行复杂接触密集型任务时控制模式的机器人学习系统。
3.How?
RDP采用双层架构:
(1)在低频下预测潜在空间中高层动作分块的慢速潜在扩散策略;
(2)在高频下实现闭环触觉反馈控制的快速非对称分词器
TactAR:Meta Quest3提供实时触觉/力反馈
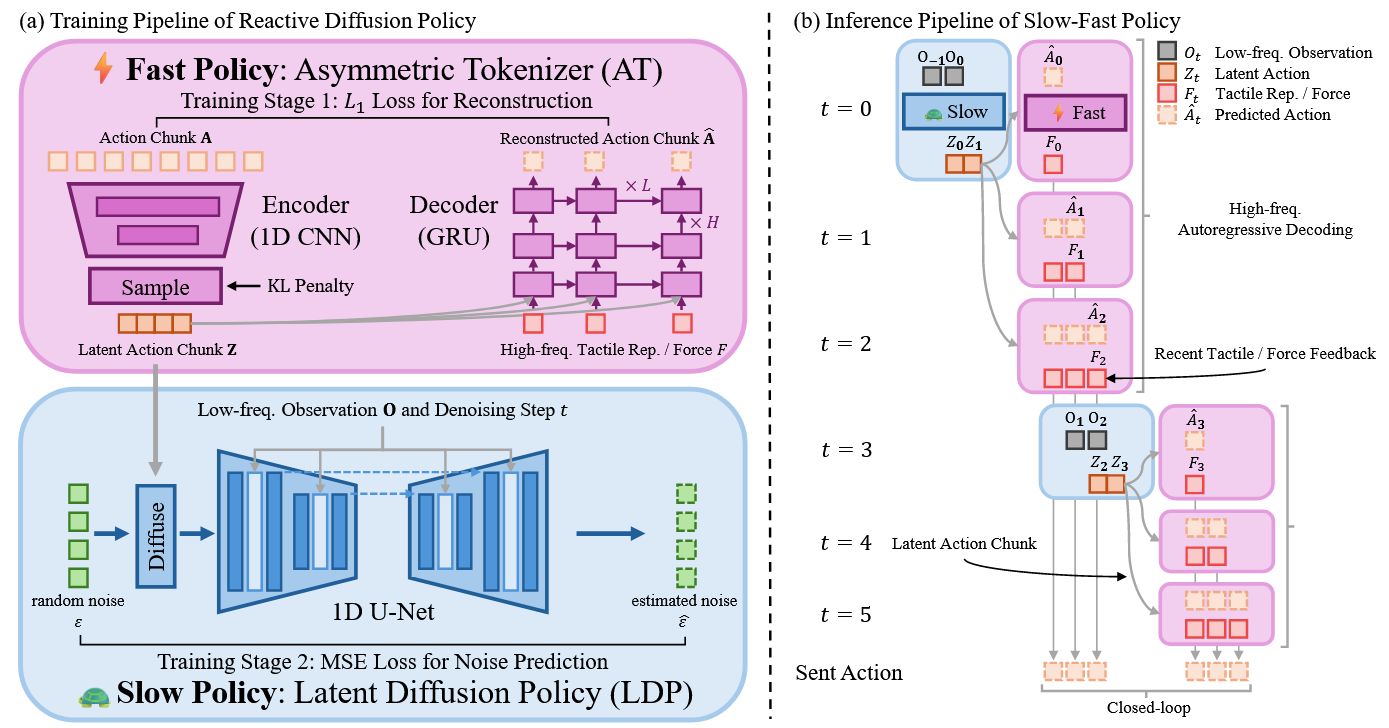
慢速网络(潜在扩散策略LDP)作为神经规划器,以低频(1-2Hz)在潜在空间预测高层动作块,类比预测性动作;快速网络(非对称分词器AT)作为可学习阻抗控制器,基于高频触觉反馈(20-30Hz)微调潜在动作块,类比闭环微调。该分层结构使慢速网络通过扩散模型和动作分块保持对复杂非马尔可夫动作的建模能力,而快速网络借助实时触觉反馈实现精确力控与快速响应的闭环控制。
首先通过训练非对称分词器将原始动作块编码至潜空间,其解码器将瞬时触觉表征与潜动作块分离作为输入;
非对称的含义是仅在解码器中将触觉表示作为输入。这种刻意设计的结构不对称性是为了确保潜在动作片段仅保留高层反馈策略,而精确位置则由解码器借助触觉信息进行预测。
策略学习阶段,慢速潜扩散策略(LDP)以类似扩散策略的方式根据观测数据预测潜动作块;
下采样后的潜在表示降低了计算成本;
AT中的不对称设计可将具有挑战性的反应行为排除在潜在动作片段之外,从而降低潜在扩散策略在低频观测下的学习难度并增强其泛化能力
推理阶段低频采样潜动作块,在每个块内执行动作时,最新触觉表征实时输入AT解码器以预测下一帧实际动作
采用相对末端执行器轨迹进行动作表征:不直接计算连续帧间的增量动作(可能导致较大累积误差),而是通过计算相对于基准坐标系的相对变换,将绝对位姿轨迹转换为相对轨迹。
我们计算策略推理与动作执行产生的延迟,并舍弃模型预测的前几个动作步,以向机器人发送精确匹配的动作
4.Takeaways:
1.在复杂接触密集型任务中,单纯将触觉信号加入观测空间未必能提升性能
2.低维触觉嵌入在评估过程中对凝胶损伤或更换导致的纹理变化展现出更强鲁棒性
3.纯视觉输入的DP常预测出偏差轨迹导致较大接触力(如图8(b)失效案例2),需人工干预防止传感器损坏;而触觉嵌入的DP虽很少产生大接触力,却易在接触物体时陷入停滞(如图8(a)失效案例2及图8©失效案例)。这可能是因为其从数据中学到了反应行为(如接触时微抬、失联时下压),但由于开环执行动作块,缺乏精细调整能力,导致在不同接触状态间快速切换
4.RDP适用于不同触觉/力传感器,RDP能同时使用左右夹爪的不同触觉传感器(左MCTac/右GelSight)保持优异表现
5.我们推测力传感器可能因其相较于光学触觉传感器具有更低延迟和更小维度而呈现更优效果,这或许降低了网络的学习难度。RDP能即时响应外部干扰
6.在剥离任务中相对轨迹预测的表现远优于绝对动作预测,这可能是因为相对轨迹更易于轻量化快速策略模型的学习由此从触觉反馈中带来了一个更具泛化能力的反应策略。此外,相对轨迹还压缩了潜在空间,促进了潜在扩散策略的学习过程。我们还发现,延迟匹配通过确保动作块之间的平滑过渡并减少分布外(OOD)行为,对策略性能提升贡献显著。
7.数据质量对于模型能力提升很重要
局限性:
1.虽然TactAR能在AR中提供一定程度的触觉/力反馈,但其直观性和效率仍不及人手直接操作
2.TactAR系统专为二指夹爪设计
3.RDP算法中的快速策略目前仅能响应高频触觉/力输入信号,尚无法快速处理高频图像输入
4.RDP算法目前仅适用于单任务场景
未来工作:
1.进一步降低传感器与系统延迟来提升远程操作效率
2.将该系统及RDP算法拓展至配备触觉传感器的灵巧手
3.考虑将高频视觉输入融入快速网络
4.可通过采用类似RDP的非对称分词器替换VLA分词器,将RDP与视觉-语言-动作模型结合,从而在VLA中引入具有实时触觉/力反馈的闭环控制反应行为。
最后放上研一人工智能课读论文环节的PPT(54-65页):
RDP | RSS 2025 | Paper Reading