$\pi_{0.5}$ | arxiv 2025.04.22 | Paper Reading
这篇文章提出了一个基础的VLA模型主要通过真机数据训练旨在让机器人可以适应家用场景。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | 基础模型VLA | 家用场景 | 2025-11-18 |
1.What?
开发了一套能够训练高度通用化视觉语言动作模型π0.5的系统,并通过概念验证表明当模型经过适当多样化数据训练后,泛化能力便会自然显现
2.Why?
目前开放世界泛化性还是一个很大的问题,需要设计能提供足够知识广度的训练方案,使机器人能在多个抽象层面实现泛化
3.How?
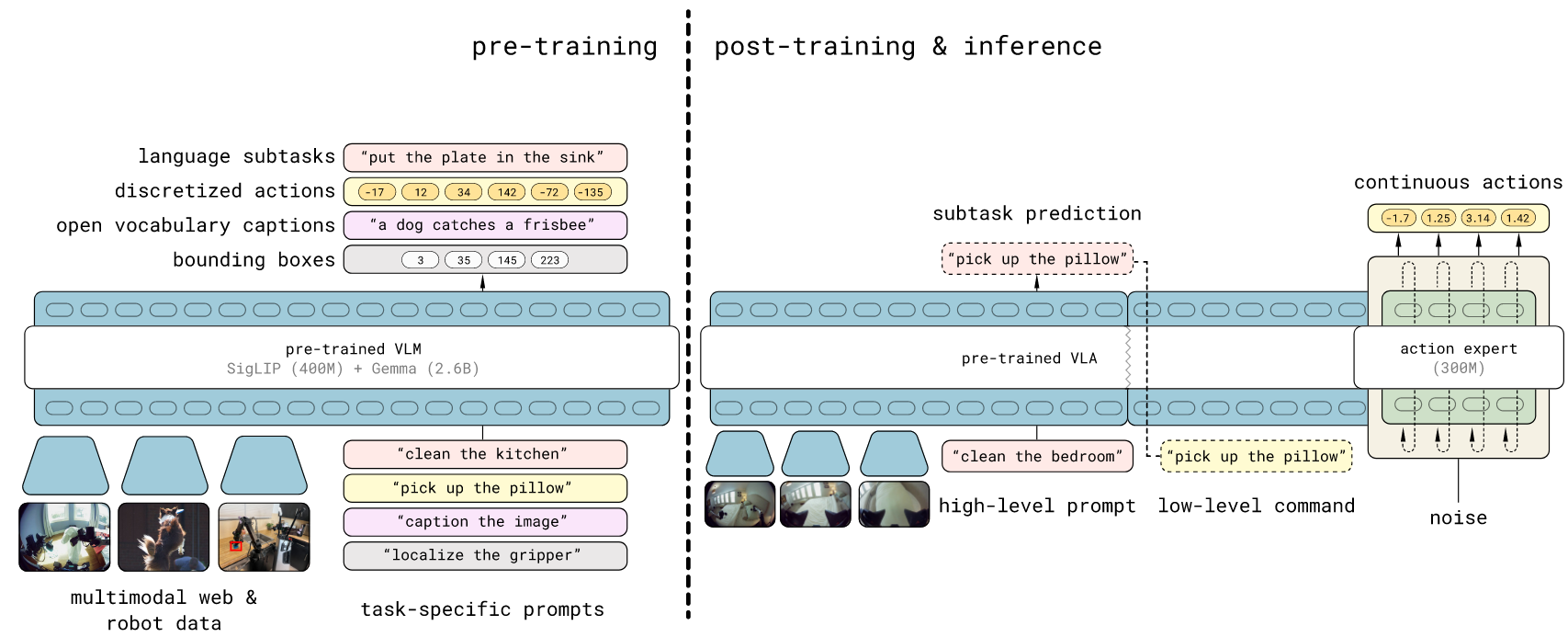
模型权重初始化自基于网络数据训练的标准VLM
训练分为两个阶段:预训练阶段旨在使模型适应多样化机器人任务,后训练阶段则专精于移动操控任务并配备高效实时推理机制。预训练期间,所有任务(含机器人动作任务)均以离散标记表示,从而实现简洁、可扩展且高效的训练。后训练期间,我们借鉴π0框架为模型增设动作专家模块,既能实现更精细粒度的动作表征,又能满足实时控制所需的计算高效推理。
在推理时,模型首先生成待执行的高层子任务,随后基于该子任务通过动作专家预测底层动作。
用离散动作标记能显著加速VLA训练——尤其当使用高效压缩动作块的标记方案(如FAST)时。但此类离散表征不适于实时推理,因其需要昂贵的自回归解码。因此理想方案是在离散动作上训练,同时保留流匹配在推理时生成连续动作的能力。为此,我们的模型通过FAST标记器的自回归采样与流场迭代积分两种方式预测动作,实现优势融合。通过注意力矩阵确保不同动作表征互不关注。
先以α=0将动作映射为文本标记,将模型作为标准VLM Transformer进行预训练;后训练阶段再添加动作专家权重以非自回归方式预测连续动作标记,实现快速推理
4.Takeaways:
局限性:
1.虽然展现广泛泛化能力,仍会出现错误。
2.某些环境存在持续挑战(如不熟悉的抽屉把手、物理上难以开启的橱柜)
3.部分行为存在部分可观测性问题(如机械臂遮挡待清洁的洒漏液体)
4.有时高层子任务推理易受干扰(如整理物品时反复开关抽屉)。
未来工作
通过改进协同训练、迁移学习和扩大数据集来解决这些挑战是未来重要方向。
$\pi_{0.5}$ | arxiv 2025.04.22 | Paper Reading