OpenVLA-OFT | RSS 2025 | Paper Reading
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
这篇文章通过对openvla进行微调并改进了action head达到了更好的效果。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | VLA | FT | 2025-10-08 |
1.What?
对于VLA提出了一种集成并行解码与动作分块、连续动作表征及L1回归目标的优化微调方案实例,在保持算法简洁性的同时显著提升推理效率、任务性能与模型输入输出灵活性。
2.Why?
面对庞大的设计空间,何种适配方法最为有效尚不明确
现有文献中对替代性微调方案的实证分析较为有限。
一些工作:
通过LoRA进行参数高效微调。然而其自回归动作生成速度(3-5 Hz)仍无法满足高频控制需求(2550+ Hz),且LoRA与自回归VLA的完全微调在双手操作任务中常表现欠佳。
3.How?
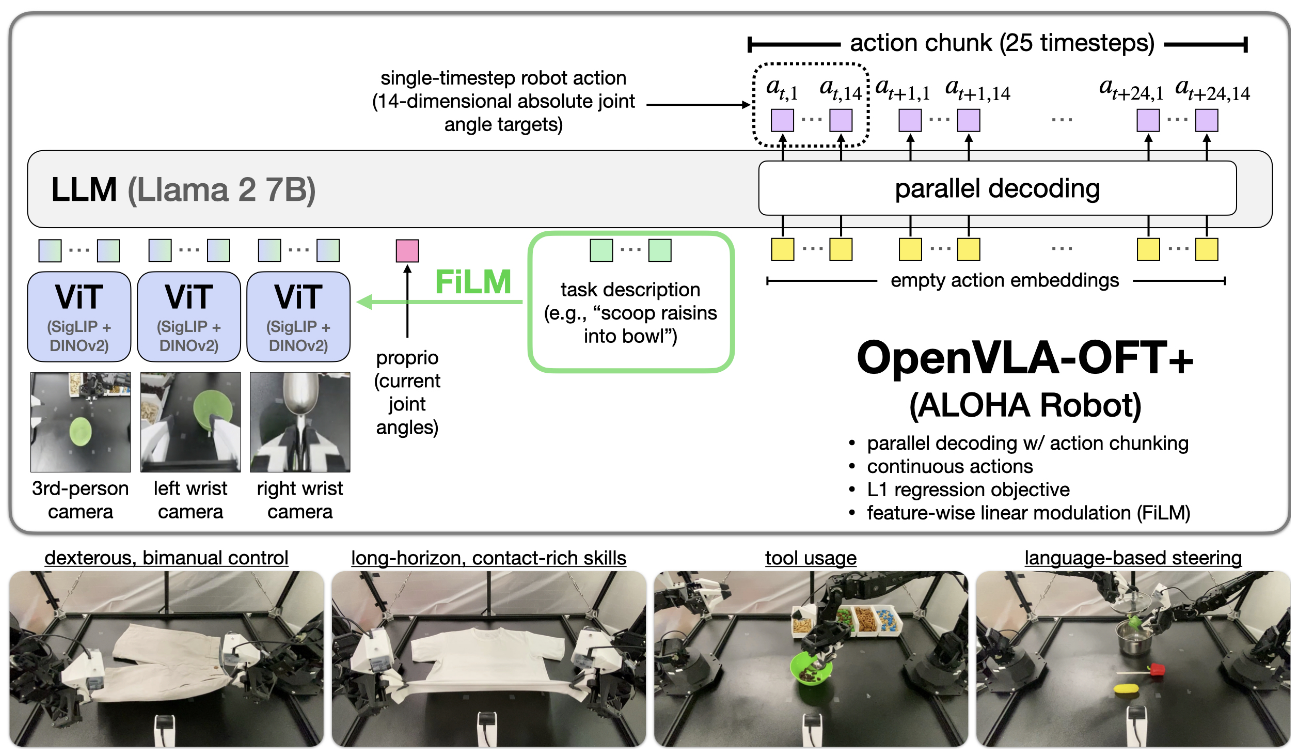
分析了三条轴线:动作解码方案(自回归vs并行生成)、动作表征(离散vs连续)及学习目标(下一令牌预测vs L1回归vs扩散模型)
并行解码:一次性输出所有动作维度;
动作块 (Action Chunking) 一次预测多步(模拟 8 步 / 实机 25 步),减少推理调用;
连续动作 + L1 回归:取代离散分类或扩散头,训练稳定、硬件友好。
微调仅增设轻量动作头与可选 FiLM 调制层,视觉‑语言主干权重保持冻结。
4.Takeaways:
(1)结合动作分块的并行解码不仅提升推理效率,还能提高下游任务成功率,同时增强模型输入输出规范的灵活性;
(2)连续动作表征相较离散表征能进一步提升模型质量;
(3)采用L1回归目标微调的VLA性能与基于扩散模型的微调相当,且具备更快的训练收敛与推理速度。
局限性&未来工作:
1.尽管L1回归通过鼓励策略学习示范动作的中位数模式有助于平滑训练示范中的噪声,但对于存在多个有效动作的真实多模态动作分布,可能难以精确建模——这在需要生成替代动作序列以完成任务的场景中可能不够理想。
2.OFT的优势是否能有效延伸至预训练阶段,抑或大规模训练需要扩散等更具表达力的算法,尚需进一步探究。
3.未配备FiLM的OpenVLA表现出较弱的语言接地能力,尽管在LIBERO仿真基准实验中未出现此类问题。
OpenVLA-OFT | RSS 2025 | Paper Reading