OpenVLA | CoRL 2024 | Paper Reading
OpenVLA: An Open-Source Vision-Language-Action Model
这篇文章基于Prismatic-7B VLM提出了一个统一的VLA模型架构。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | VLA | 统一VLA模型结构 | 2025-10-08 |
1.What?
一个基于97万条真实机器人演示数据训练、拥有70亿参数的开源VLA模型
2.Why?
- 现有VLA模型大多为闭源系统,公众难以访问;
- 先前研究未能探索高效微调VLA以适应新任务的方法——这正是推广应用的关键环节。
3.How?
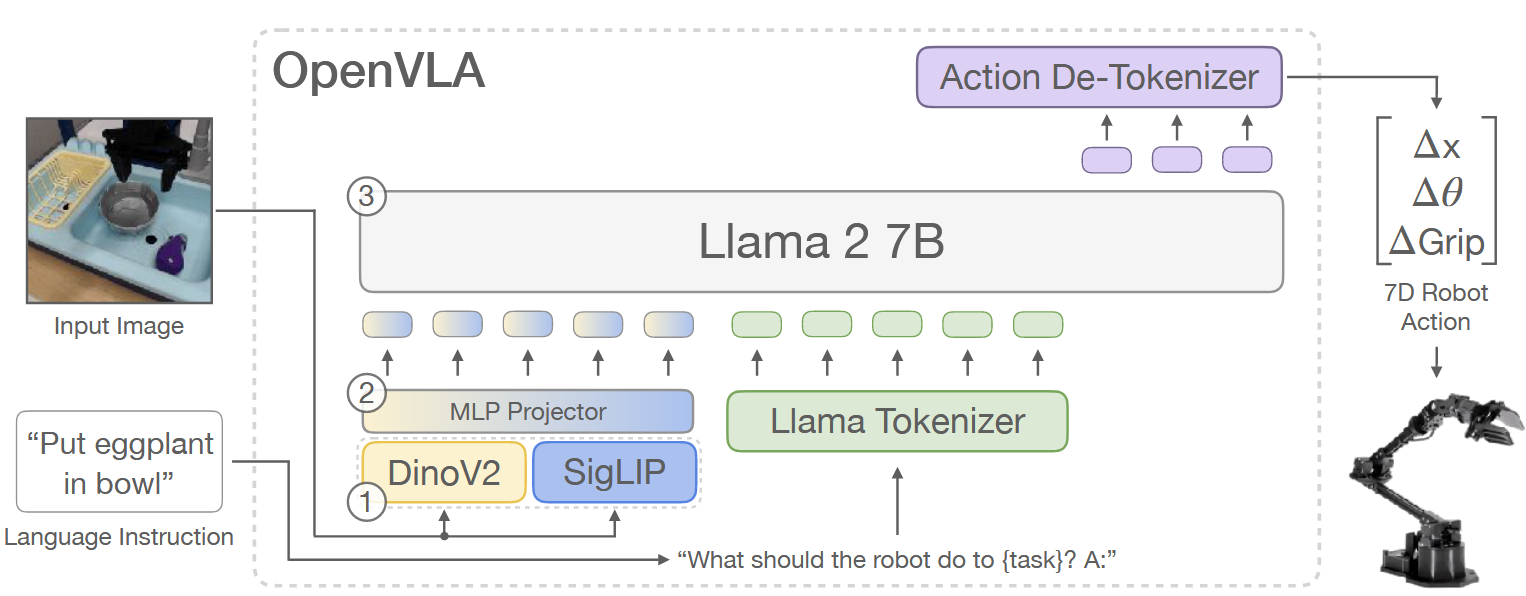
OpenVLA 基于 Prismatic-7B VLM,该模型采用标准 VLM 体系结构,包含600M参数的视觉编码器(由预训练的SigLIP和DINOv2构成)、一个小型的双层 MLP、一个7B参数的 Llama 2 骨架。
特征融合:
输入图像 Patch 先分别通过 SigLIP 和 DINOv2 进行编码;
将两个编码器的输出特征在 channel-wise 上拼接。
与 CLIP 或单独使用 SigLIP 的编码器相比,DINOv2 额外提供的特征可以增强空间推理能力,这对于机器人控制尤其重要。
为了训练 OpenVLA,作者对预训练的VLM backbone 进行微调,以让其拥有机器人动作预测的能力(见 Fig. 2 红框中的部分),将机器人动作预测问题定义为一个VL任务。
输入:观察图像+ 自然语言任务指令;
输出:映射为 一串预测的机器人动作;
为了使 VLM 模型能够输出机器人动作,作者将动作表示为 LLM 输出空间中的离散 token,将连续的机器人动作映射到语言模型使用的 token,每个机器人动作维度被离散化为 256 个区间,区间宽度设置为均匀划分训练数据中 1% 到 99% 的分位数。使用分位数可以忽略数据中的异常动作,避免扩展到离散化区间。
在这种离散化方式下,将 N 维机器人动作映射为 N 个离散整数,其值范围在 ∈ [ 0 , 255 ]。
OpenVLA 采用的 Llama 分词器仅预留了 100 个“special tokens” 用于微调时新增的tokens,而这和上面所提到的机器人 256 动作区间存在冲突。为了解决这个问题,作者选择了一种简单的方法:直接覆盖 Llama 分词器词表中最少使用的 256 个tokens(即最后 256 个tokens),将它们替换为上面的动作tokens。
一旦动作被转换为tokens序列,OpenVLA 以标准的“预测下一个tokens” 为目标进行训练,仅对预测的动作tokens计算交叉熵损失
4.Takeaways:
1.未发现由于分辨率的增加而带来的显著的性能差异
2.在 VLA 训练期间微调视觉编码器对于获得良好的 VLA 性能至关重要
3.对于 VLA 而言,反复遍历训练数据集的意义要多得多
4.未发现学习率预热能带来任何性能提升
局限性&未来工作:
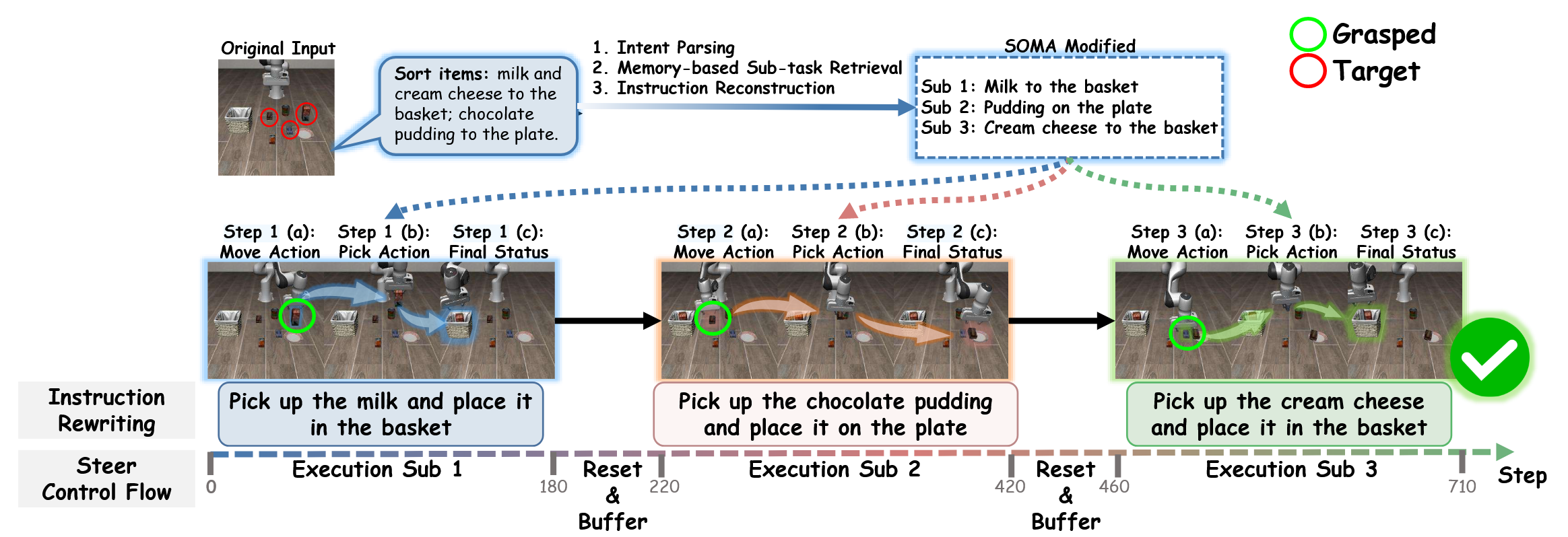
1.将 Diffusion Policy 中的 action chunking 和 temporal smoothing 机制融入 OpenVLA,可能有助于提升其操作灵巧性,使其达到与 Diffusion Policy 相同的精确度。
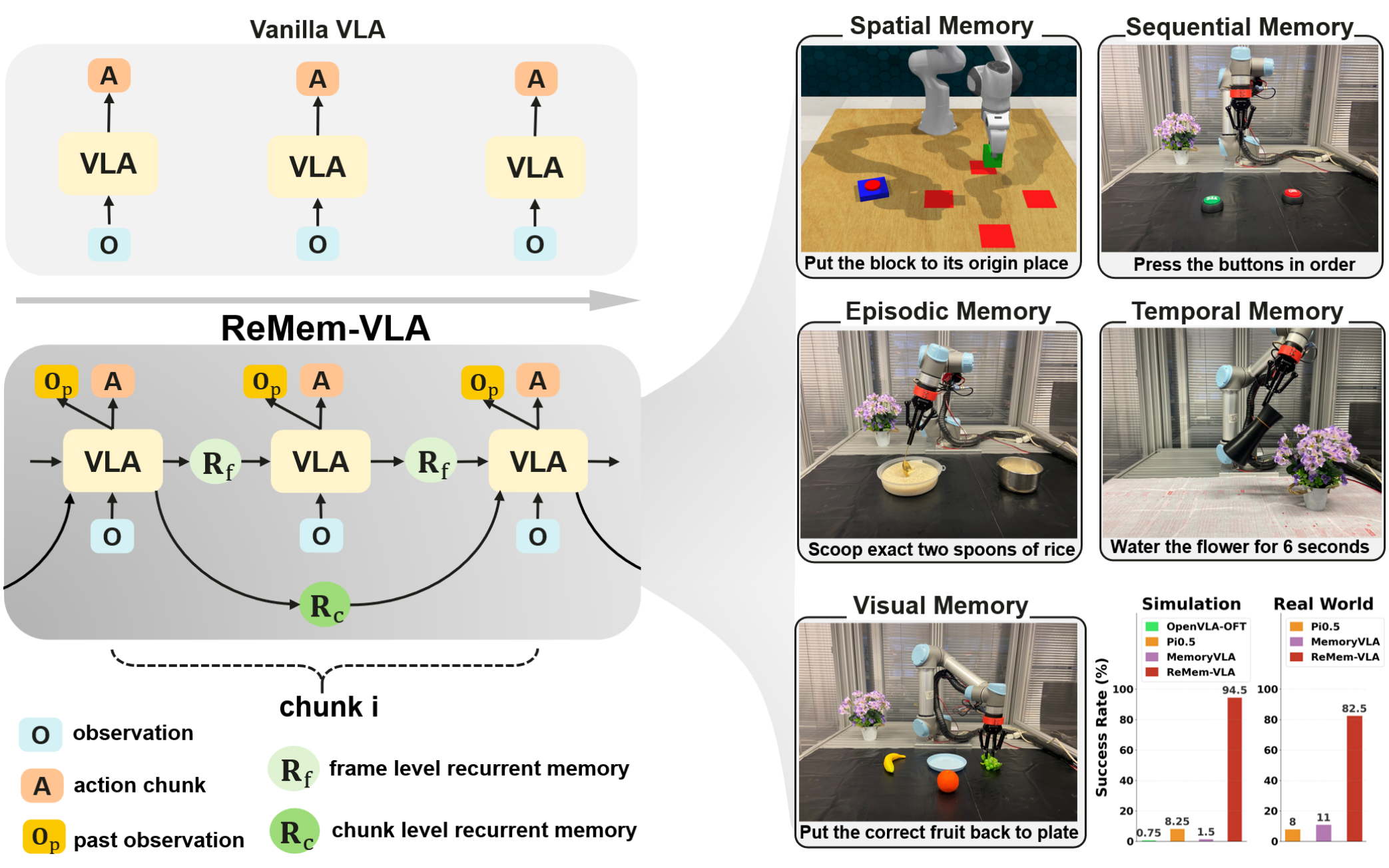
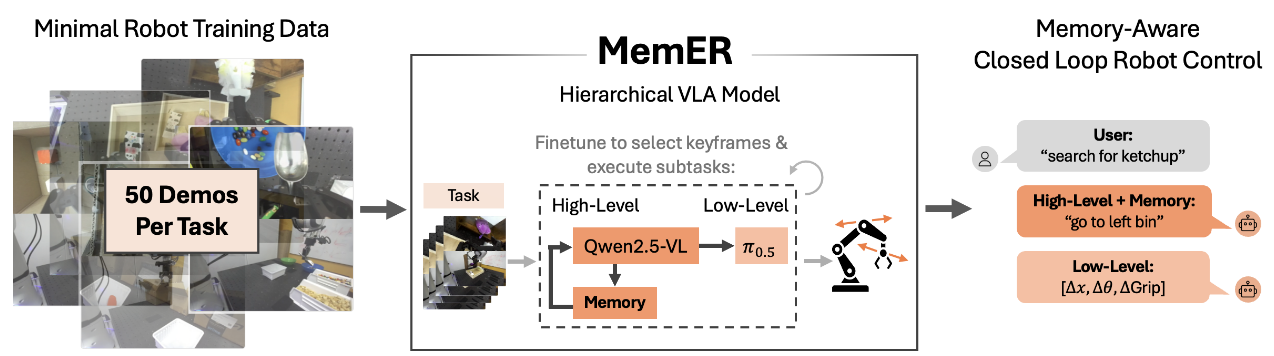
2.目前仅支持单图像输入,而在实际中,机器人硬件是异质的,拥有各种不同的感知输入。因此扩展 OpenVLA 以支持多图像、本体感知输入、保留历史状态,是未来工作中的一个重要方向。或许在图像文本交替数据集上预训练的 VLMs 会有助于这种灵活输入的 VLA 微调;
3. 提高 OpenVLA 的推理吞吐量以实现高频控制(如 ALOHA 运行频率为 50Hz),这还可以让双手操作任务上测试 VLA 成为可能。探索 action chunking 或其他推理优化技术(如,预测性解码 speculative decoding)可能是解决这一问题的潜在方法;
4. 尽管 OpenVLA 超越了以往的通用模型,但在测试的任务上其可靠性仍有待提高,通常成功率低于 90%。
5. 由于算力限制,许多 VLA 结构的问题尚未得到充分探索:
- 基础 VLM backbone大小对 VLA 性能有什么影响?
- 使用机器人动作预测数据、互联网规模的VL数据共同训练,是否会显著提升 VLA 性能?
- 哪些视觉特征最适合用于 VLA 模型?
OpenVLA | CoRL 2024 | Paper Reading