InternVLA M1 | arxiv 2025.10.15 | Paper Reading
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
这篇文章提出了一个空间引导的VLA基础模型。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | VLA | 空间引导 | 2025-11-05 |
1.What?
InternVLA M1 一个空间引导的VLA模型
2.Why?
序列动作生成中的时间冗余和视觉输入中的空间冗余
3.How?
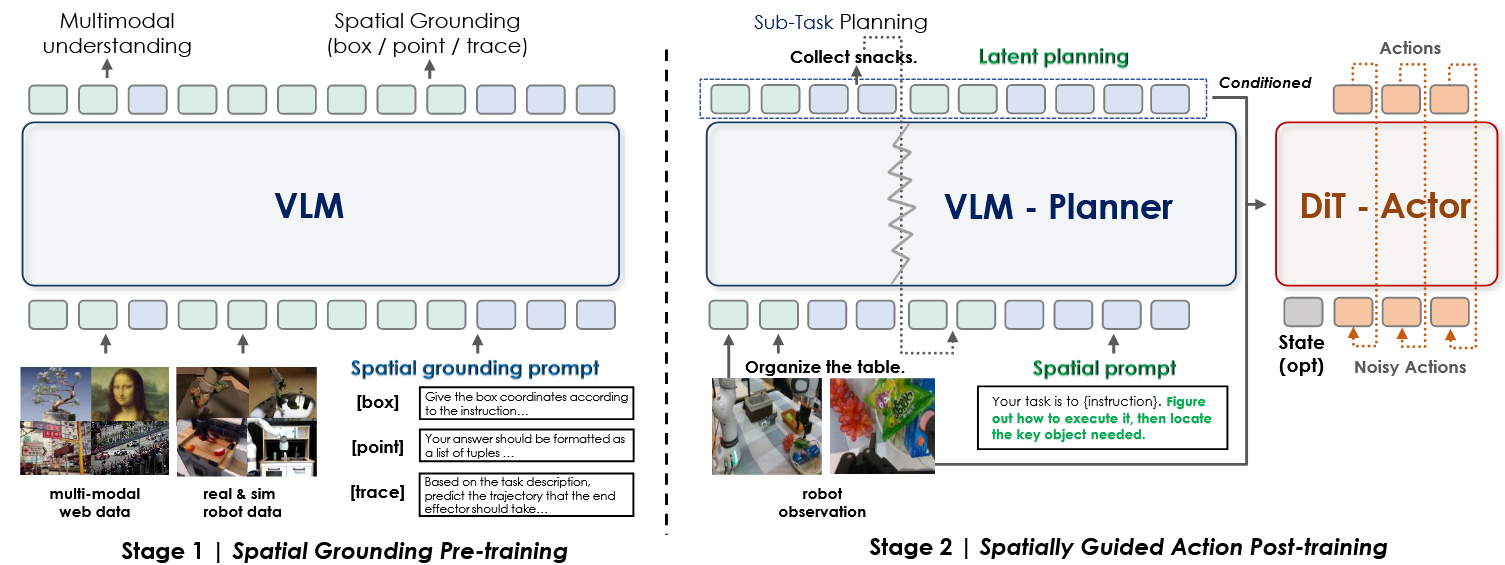
System 1 动作模型(Actor)采用 DiT 模型架构,具备独立的视觉和状态编码器,专注于动作生成和精细控制。
System 2(VLM Planner) 基于预训练的多模态大模型作为视觉语言编码器,专注于空间理解和动作规划。在训练中同时引入视觉理解和动作联合监督,通过联合梯度优化实现视觉语义理解与运动控制的协同学习。
Querying Transformer 将变长输入映射为固定的隐藏空间特征,并通过跨层注意力机制选择性连接 VLM 的中间层,为动作专家提供高层语义信息与动作规划先验信息。
训练:
空间感知预训练:主要解决“看到”(Where to act)的问题,VLM 充分预训练多种空间感知表征,确保对目标和规划的精确定位;
基于空间规划的动作后训练:主要解决“做到”(How to act)的问题,通过空间提示将任务指令提取隐藏空间信息,提升机器人执行的稳定性和效率。例如,在“把玩具放进玩具箱”的任务中,模型会先识别玩具和容器,转化为嵌入特征,指导精准完成任务。
数据集:合成了专门面向抓取任务的 InternData·M1 数据集
4.Takeaways:
局限性&未来工作:
InternVLA M1 | arxiv 2025.10.15 | Paper Reading