InternVLA-A1 | arxiv 2026.01.05 | Paper Reading
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
这篇文章提出了一个基础VLA模型,主要聚焦于解决快速移动场景的机器人操作能力。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | VLA + 提升领域能力 | 快速移动操作能力 | 2026-01-05 |
1.What?
一个统一的混合专家Transformer架构,协调场景理解、视觉前瞻生成和动作执行三个专家模块,这些组件通过统一的掩码自注意力机制无缝交互。
基于InternVL3与Qwen3-VL框架,我们构建了20亿和30亿参数规模的InternVLA-A1,在InternData-A1和Agibot-World混合合成-真实数据集上进行预训练,在12项真实世界机器人任务和仿真基准测试中表现显著优于π0和GR00T N1.5等领先模型,在日常任务中提升14.5%,在动态场景(如传送带分拣)中实现40%∼73.3%的性能提升
2.Why?
当前主流的VLA模型本质上缺乏对物理世界动态的推理能力。因此,近期研究转向世界模型方向,这类方法通常通过视频预测实现;然而,此类方法往往缺乏语义基础,且在处理预测误差时表现出脆弱性。
现有策略的泛化瓶颈主要源于两大问题:物理世界认知不足与自适应操作能力缺失。
物理世界认知不足:
解决方法:需融合多模态大语言模型或世界模型等基础模型以增强认知能力
自适应操作能力缺失
解决方法:需大规模、多样化的机器人数据集进行技能学习。
3.How?
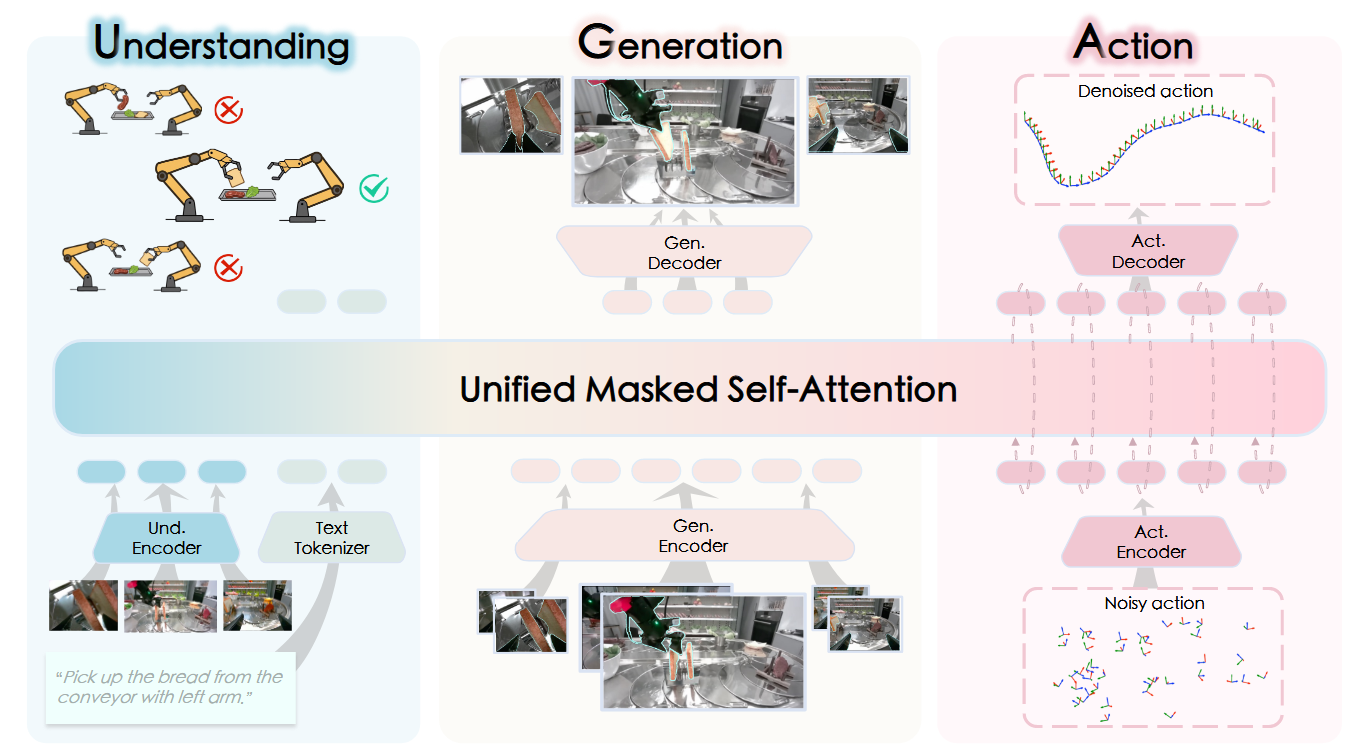
MoT架构:InternVLA-A1在统一流程中部署了三位专家:理解专家首先处理多模态输入以捕捉环境上下文;这些表征随后传递给生成专家,通过预测未来状态来模拟任务演进;最终,动作专家将这些预测动态与语义上下文相结合,并利用流匹配技术生成精确的机器人控制指令。
理解专家。理解专家直接采用现有MLLM的架构。在本实现中,我们采用InternVL3或Qwen3-VL,其优势在于原生多模态能力以及语言与视觉间的强对齐性。我们遵循基础MLLM的处理流程:将时刻t的多视角观测ot通过集成视觉编码器编码为视觉标记,同时语言指令l通过文本分词器转换为文本标记。这些视觉与文本标记随后被拼接为前缀标记
生成专家。受统一多模态模型Janus Pro的启发,我们采用解耦的视觉编码策略以应对理解与生成任务的不同需求。理解任务需要通常由基于ViT的编码器捕获的高层语义抽象,而生成任务则需保留细粒度空间结构与像素级保真度。为弥合这一差距,我们的生成专家采用基于VAE的分词器,该分词器在图像与视频生成中广泛应用,能够将视觉数据压缩至专为高质量重建优化的潜空间。具体而言,我们使用Cosmos CI8×8连续VAE分词器将输入图像编码为连续潜特征,为后续生成过程提供稠密且结构丰富的表征。该分词器包含编码器与解码器;我们将其编码器记为 φ_{cosmos},并使用解码器从潜变量重建图像。令 z_t = φ_{cosmos}(o_t)表示时刻t的Cosmos潜变量;在 h_{und}与 {z_{t−m}, z_t}的条件下,生成专家预测 \hat z_{t+m}。
传统的图像与视频生成模型——无论是基于扩散方法还是基于下一令牌预测——通常难以满足高频实时推理的需求。即使是经过优化的解决方案如SANA-Sprint也需要每生成0.16秒,将控制频率限制在6Hz以下。这一局限阻碍了机器人流畅运动,凸显了具身AI领域对更快视觉生成机制的迫切需求。
在我们先前的工作F1中,我们采用下一分辨率范式进行视觉前瞻生成。该方法虽然有效,但需要迭代前向传播,这损害了VLA任务所必需的实时推理能力。因此,我们采取了更激进的设计策略以优化性能。我们使用Cosmos CI8×8连续VAE图像分词器处理两个时间戳(当前帧与历史帧)的三视角图像。输入图像调整至256×256分辨率后,每帧首先被编码为32×32的潜在特征图。若直接将潜在令牌输入生成专家模块会导致序列过长,影响推理效率与训练收敛。为缓解此问题,我们通过卷积层将各潜在特征的空间维度压缩至4×4(每幅图像仅用16个令牌表示),并利用投影器将其对齐至变换器的隐藏维度。这些压缩令牌随后输入生成专家模块,通过多层掩码自注意力机制与前缀令牌hund(推理时以键/值形式缓存)交互。其隐藏状态经时序池化后形成预测的未来潜在表示
动作专家模块 在语言目标l、当前观测ot(通过前缀令牌hund)、本体感知qt以及生成专家模块预测的潜在令牌 \hat z_{t+m}的条件下,预测目标动作块 \hat a_{t:t+k}。我们采用流匹配目标训练该VLA模型。
注意力机制方面,我们在理解、生成与动作专家的级联令牌流上实施分块注意力掩码。累积分段掩码强制执行严格的信息流向:理解→生成→动作。后部块中的令牌可关注所有前部块,而前部块不能向前关注。前缀块(视觉+语言)为完全双向注意力。生成块同样为完全双向注意力,且仅接收来自第t-m帧与第t帧的Cosmos潜在令牌。动作块被划分为状态令牌与动作令牌:状态令牌仅关注自身及前部块,而动作令牌可关注状态令牌及彼此。
4.Takeaways:
强调了真实世界和仿真数据同样重要
局限性:
首先,理解专家模块目前未与多模态视觉问答数据集进行联合训练,导致通用语义推理与复杂指令跟随能力有所下降;
其次,为保证视觉前瞻模块的推理效率,我们在图像预测的保真度上做出了妥协,这限制了生成未来帧的精细度。后续研究将针对这两项局限展开改进。
未来工作
InternVLA-A1 | arxiv 2026.01.05 | Paper Reading