FiSVLA | arxiv 2025.6.02 | Paper Reading
Fast-in-Slow: A Dual-System Foundation Model Unifying Fast Manipulation within Slow Reasoning
这篇文章将双系统架构中的系统1嵌入到系统2中从而得到更好的结果。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | 双系统VLA | 系统一嵌入系统二 | 2025-10-14 |
1.What?
创新性地将快系统嵌入到基于VLM的慢系统中实现了快系统的快速执行和慢系统的推理能力
目的是改善双系统VLA协作的性能和效率
2.Why?
1.之前工作已经证明基于vlm框架将动作离散为一个个的token来自回归地预测的效果不好
2.于是有了一种新的范式即先用一个VLM做慢速推理再用一个DP或者flowMatching的Transformer做动作执行
那么如何链接两个模型就是影响系统的关键
之前的双系统有:
1.同步双系统:PI0,CoT-ACT,GRootN1
同步的意思是两个系统接收的observation输入的频率一致且都是从慢系统输入,两个系统之间主要通过慢系统输出多模态特征(hidden states),系统1主要是通过Action建模,可以接受一些额外的输入(robostates)
问题:1. 快系统需要和慢系统的工作频率一致,限制了action生成的效率。虽然有一些改进:action输出token时是一次全输出token而不是逐token,但仍然效率低 2.慢系统仅仅作为一个特征提取器无法让后面的快系统充分利用其reasoning的能力(这里快系统都是没有经过大规模互联网数据进行过预训练的,也就是没有很好的推理能力)
2.同步子任务分解双系统:在前面的基础上对于输入慢系统可以将长程任务分解为一个个原子任务再将原子任务输入快系统中,对action建模做一个condition。原子任务更好理解和学习,故对快系统更友好,直观地体现了快系统的推理能力,但由于双系统依然同频工作所以链接虽是通过子任务链接,子任务仍要经过VLM理解再输入给快系统进行action建模的condition。子任务输入到系统中还是通过hidden states,还是存在前面的两个问题
3.异步双系统架构:工作频率不同,observation 输入到慢系统后在接下来n个时间中没将慢系统中每个observation都输入到慢系统中去让模型理解而是通过Dt时刻延迟的指导信息一直在指导n个时刻系统1的学习一定程度上提高了系统1的执行频率,但问题是系统1,2的连接仍然是通过慢系统输出的hidden states进行连接的,还是存在问题
3.How?
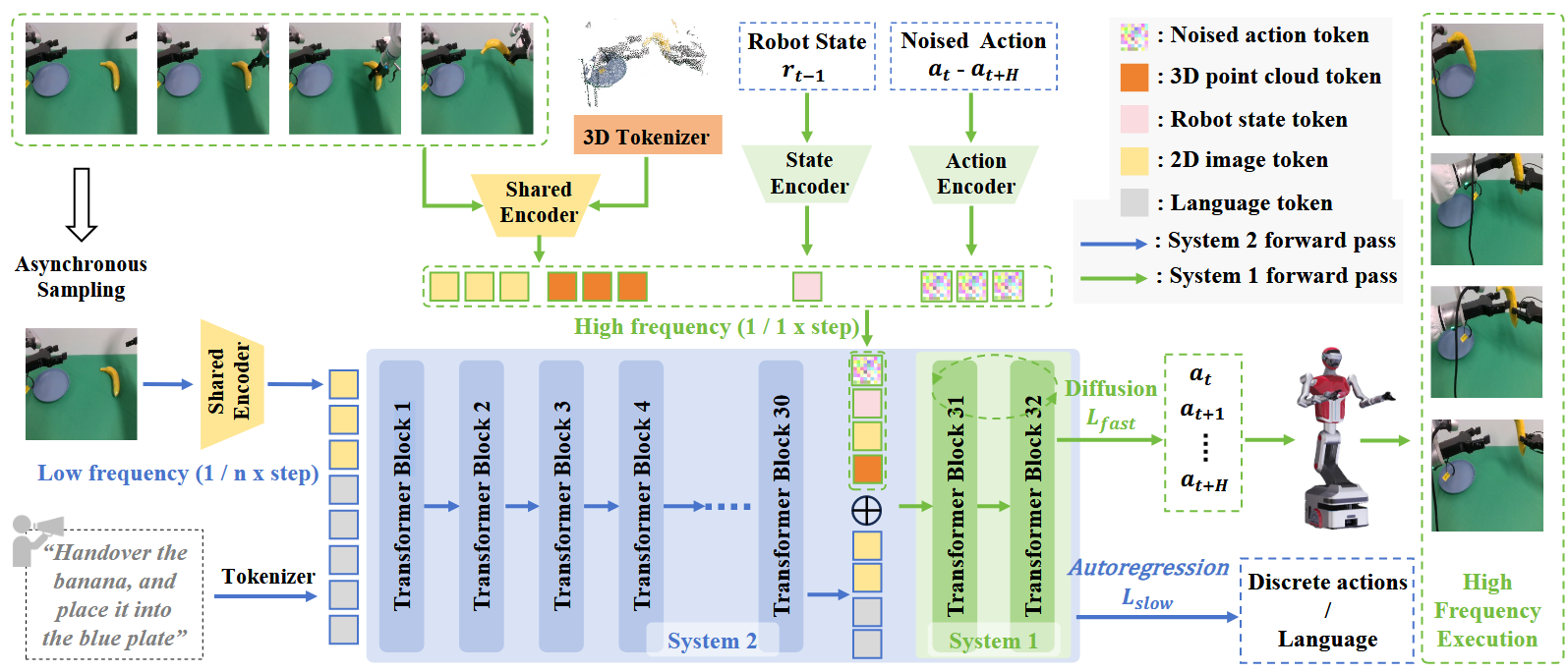
与前面工作不同作者希望能融合两个模型,具体是通过将快系统嵌入慢系统中。
慢系统是由vision encoder和LLM backbone组成,而快系统就是将慢系统的LLM backbone的最后两层以及shared encoder作为快系统
慢系统输入的是2d图像和语言instruction,快系统输入的是2d图像和3d点云和robot state
用diffusion loss 监督快系统输出的action,为了保留慢系统复杂任务的拆解能力用了CE-loss(自回归的loss)去监督VLM输出的离散的actions或者subtask language。
初始化预训练参数之后用了86万条机器人数据进行训练再在下游任务上微调
4.Takeaways:
1.作者探究了当慢:快=1:4的频率时效果最好
2.点云对于慢系统提升作用不大反而会影响效率,所以最后没有加
FiSVLA | arxiv 2025.6.02 | Paper Reading