3D Diffusion Policy | RSS 2024(oral) | Paper Reading
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
这篇文章将Diffusion应用到3D空间。是在diffusion policy基础上进一步提升了策略的能力。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | Diffusion Policy | 将Diffusion Policy扩展到3D空间 | 2025-10-02 |
1.What?
DP3 = DP+3D
一个模拟基准( 7 个领域的 72 个不同机器人任务,以及 4 个真实世界任务,包括在可变形物体上进行具有挑战性的灵巧操作)
优势:
更高的准确性,更少的演示数量和训练轮数
泛化至空间、视角、实例和外观等多个方面
安全 在实际任务中很少发出不稳定的指令
2.Why?
以往仅用3D进行控制的方法推理速度太慢,使用预测和规划的方式低维中有成效但不适合高维控制
3.How?
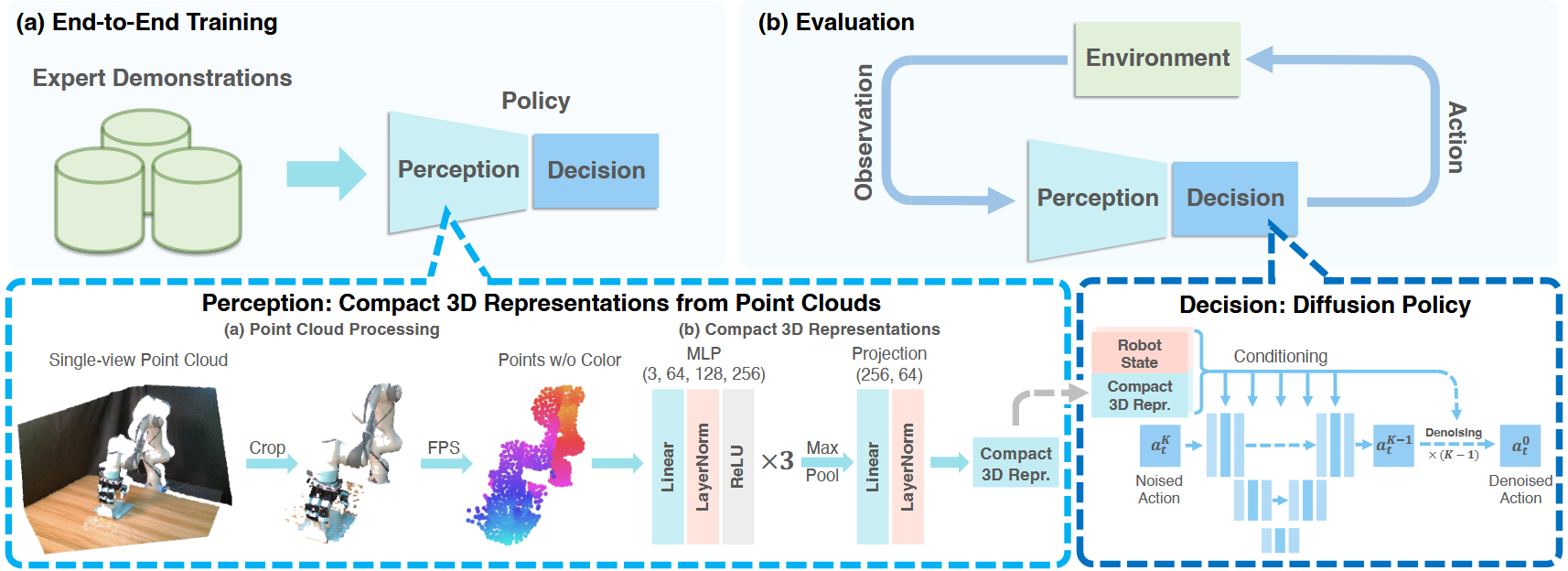
Perception:Encoder: MLP x 3 + maxpooling + Linear + LN (Single viewed)
Decision:Decoder: 条件去噪扩散模型 CDDPM
裁剪点云有助于大幅提高精度
加入LayerNorm层有助于稳定不同任务的训练
DP3编码器中的投影头通过将特征投影到较低维度来加速推理,而不会影响精度
去除颜色通道确保了鲁棒的外观泛化
在低维控制任务中,DPM-solver++ 作为噪声采样器与DDIM相比具有竞争力,而DPM-solver++难以很好地处理高维控制任务
4.Takeaways:
简单的点云表示优于其他复杂的三维表示,也更适合扩散策略而非其他策略骨干
局限性与未来工作:
用于控制的最佳 3D 表示仍有待发现
这项工作没有深入研究具有极长视野的任务,这有待于未来的探索。
3D Diffusion Policy | RSS 2024(oral) | Paper Reading