Diffusion Policy | RSS 2023 | Paper Reading
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
这篇文章是将Diffusion应用到Robotics的开山之作,引出了很多衍生文章。很值得学习和阅读去了解diffusion policy。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | Diffusion Policy | 将Diffusion用到了robotics中 | 2025-10-02 |
1.What?
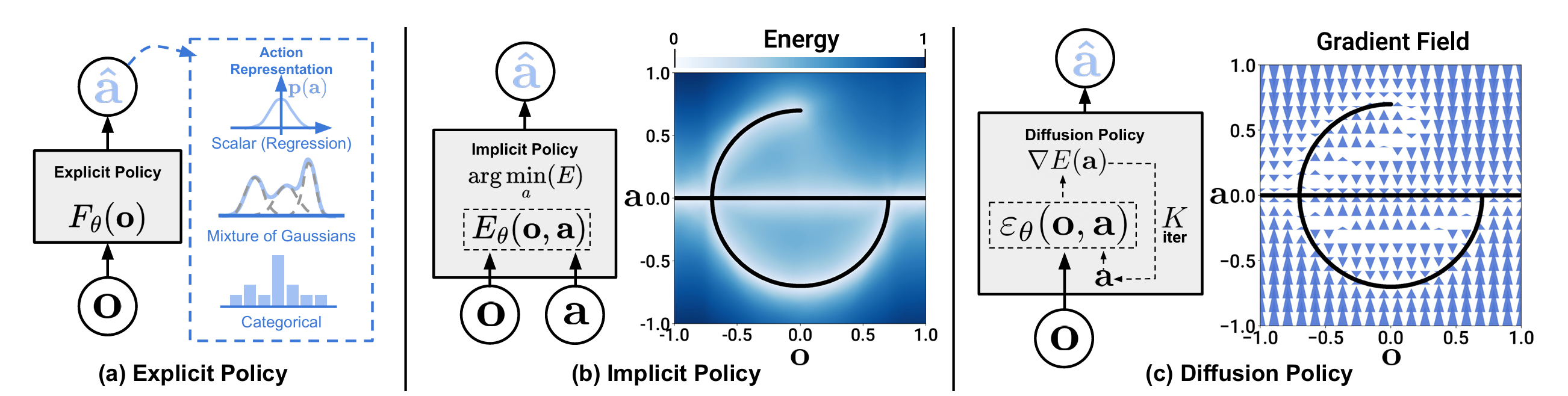
将视觉运动策略表示为条件去噪扩散模型,称为扩散策略
在机器人动作空间上进行条件去噪扩散过程,根据视觉观测推断动作-评分梯度
策略内包含:后退水平控制、视觉条件约束以及时间序列扩散Transformer三种机制,来具体实现模型
2.Why?
之前的工作采用高斯混合模型、量化动作的类别表示、通过转换策略表示形式——从显式转为隐式以更好地捕捉多模态分布
作者希望将图像领域的扩散模型用到机器人领域,原来生成图像,现在生成动作
3.How?
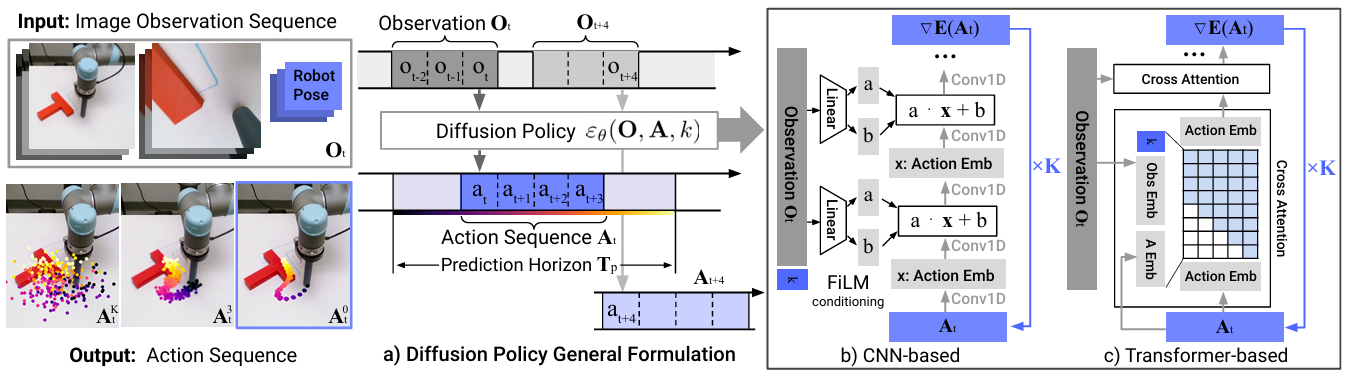
ResNet-18(前端抽取图像特征) + CNN-based/Transformer-based 模型训练学习不同程度noise加入action的输入输出为原先的groudtruth action学习到这种能力(MSE更新学习FiLM输出的参数以及其他网络参数)后进行推理,输入一个Obs,模型经过k步迭代最后得到预测的下一个Action机器人执行后获得新的Obs,如此反复直到完成任务
4.Takeaways:
归一化处理对于扩散策略获得最佳性能很重要
旋转表征:6D旋转表征
图像增强:随机裁剪
基于CNN的DP优于基于Transformer的DP结构
局限性与未来工作:
行为克隆的固有局限,如演示数据不足时性能欠佳。扩散策略可应用于强化学习等其他范式,以利用次优和负面数据。
相较于LSTM-GMM等简单方法,扩散策略具有更高计算成本与推理延迟。我们的动作序列预测方法部分缓解了该问题,但可能无法满足高频率控制任务需求。
未来工作可借助扩散模型加速技术的最新进展来减少所需推理步数。
Diffusion Policy | RSS 2023 | Paper Reading