CoA-TAM | NIPS 2025 | Paper Reading
Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
这篇文章的核心思想是将原先的顺序轨迹改为逆向的预测。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | CoA | Inverse trajectory | 2025-10-14 |
1.What?
提出了一个基于轨迹自回归建模的VLA致力于提升具身操作能力
2.Why?
1.目前的工作都是前向预测,而前向预测每一步都会有一个误差然后就无法处理OOD问题
2.作者思路将前向改为后向倒着一步步推理回去直到起点(采用绝对坐标)
3.How?
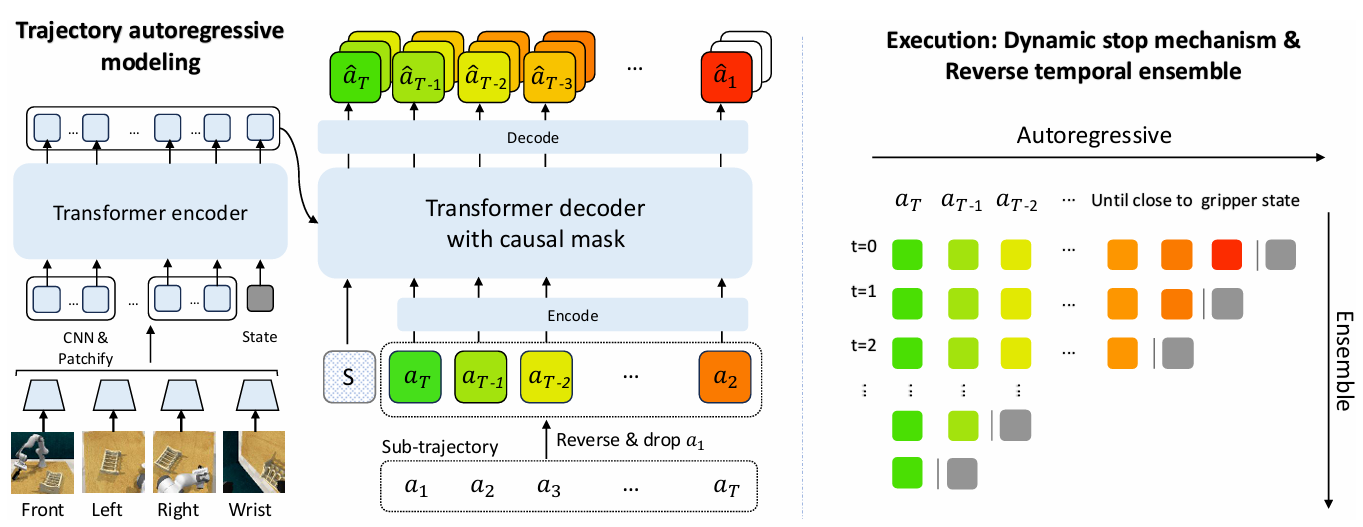
用ACT作为baseline在此基础上去掉了ACT encoder中的VAE部分,保证encoder和decoder层数一样
在decoder处将一次forward改为自回归形式(类似于语言模型)
不用离散的token(大量工作已经证明了这种方式不好)
用连续的就需要加一个约束让他停下来(没有结束token提示)
四个关键设置
连续动作表征,避免离散化引起量化误差,用了latent consistency loss
动态停止机制 基于距离的停止机制,实现可变长度的轨迹预测
反向时间集成 反向的时序集成
多词元预测 仅在训练阶段作为正则化手段建模动作的局部依赖关系,推理时移除以保持效率
4.Takeaways:
1.Goal conditioned加了就有用(CoT-VLA中已经探索)
2.空间连续性很重要,如果预测时采用双向的方式反而不好,因为长程空间跳跃建模难度大导致模型拟合能力弱
3.更多的关注算法,释放现有数据的潜力,动作本身如何建模值得研究
4.action horizon很重要,大的horizon能更好的感知全局任务意图
5.但是大的horizon在现实中会导致更大的延迟和降低灵活性,所以如何更好植入全局任务意图进行上层规划并建立上层规划到动作生成的约束很值得探索
局限性&未来工作:
1.关键帧定义还比较局限于启发式规则,就是一个个点,未来考虑用位姿做关键帧
2.推理速度还比较慢(因为是自回归的)
3.依赖动态停止,目前停止的还不好,需人为调试才行(要调比较久)
CoA-TAM | NIPS 2025 | Paper Reading