BridgeVLA | NIPS 2025 | Paper Reading
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
这篇文章基于OpenVLA将嵌入空间投影到共享空间从而进行更好学习。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 改进 | 3D VLA | internal heatmap | 2025-9-14 |
1.What?
提出了预测heatmap的新范式的3D VLA
2.Why?
1.目前VLA模型在在2D上效果很好,能不能将其拓展到3D上?
3D-VLA之前的工作还有一些问题:
WM-based:高数据效率,分级模块会有累计误差
pointVLA:将2d信息送入VLM中将3D信息单独用pointcloud encoder提取对应的特征,将VLM输出的token传给action expert之后与3D信息进行concat在输出动作
lift3D:给2D基础模型3D操作能力
1.隐式表征提取:通过重建场景的深度来让模型学到这种隐式的表征
2.显示具身操作:输入点云
spatialVLA:2D 图像+深度估计(每一个像素的深度)+得到每个像素的3D位置,将3D位置无空间结构Token转换为相应的embedding和无空间的Token
3.How?
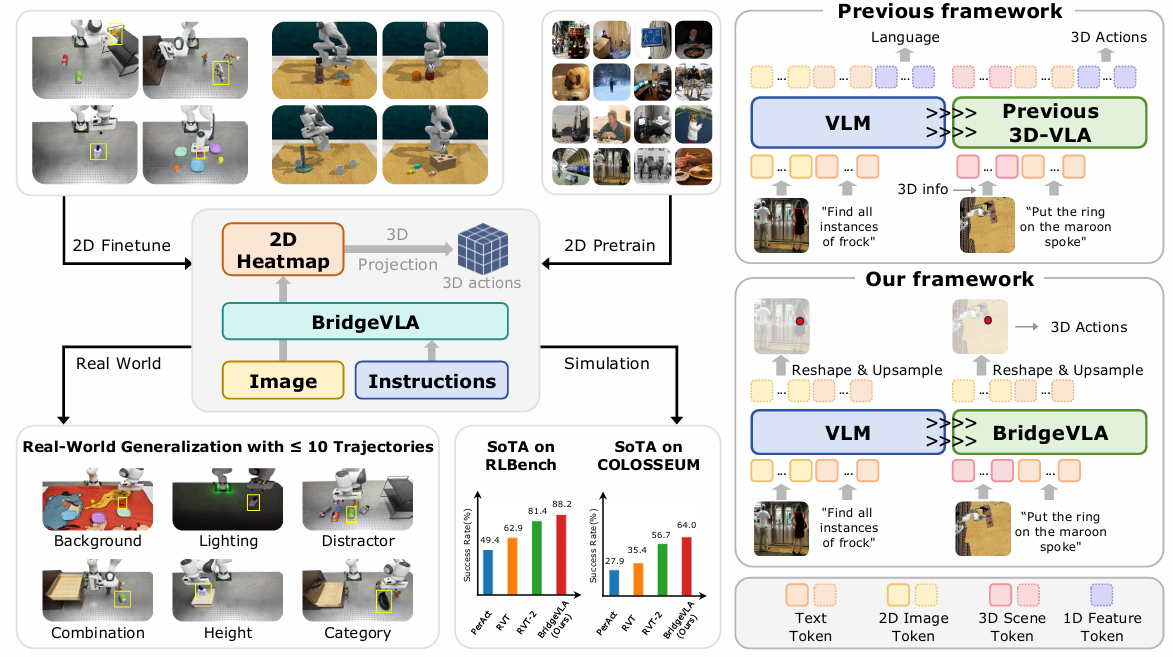
insight:将预训练和微调阶段的输入输出全对齐到一个共享的2D空间可以减小Gap使3DVLA的潜力发挥
将openVLA模型的主体结构的输出进行了调整,不再输出Token而是先生成一个heatmap(VLM&VLA)
再将其解码得到一个3D Action
4.Takeaways:
局限性:
1.在未见类别上表现不好
原因:VLM无法很好帮助指导悬空的点;预训练数据较完美的第三人称视角,单微调图像有残缺
未来工作:
1.更好的预训练
在图像输入数量上对齐;用更多类型的数据
2.灵巧操作
叠衣服
组装纸盒
扔抓
BridgeVLA | NIPS 2025 | Paper Reading