ACoT-VLA | arxiv 2026.01.16 | Paper Reading
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
这篇文章提出了一个基础VLA模型,主要为VLA模型加入了动作链推理。
| 工作类型(首次/改进) | 技术路线 | 创新点 | 日期 |
|---|---|---|---|
| 首次 | VLA + action CoT | action CoT | 2026-01-16 |
1.What?
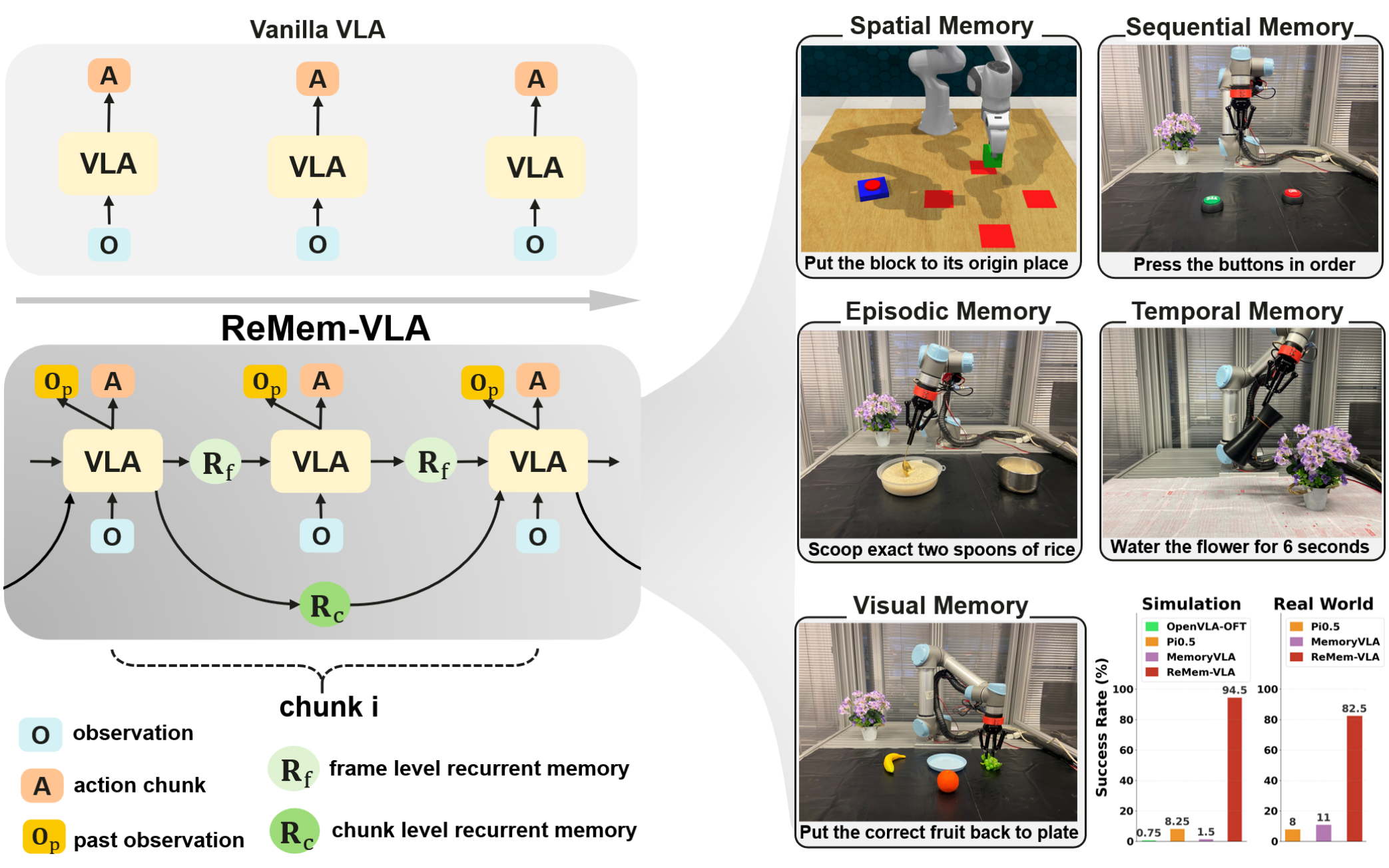
一个在动作空间中进行推演的VLA模型,通过两个互补的组件显式动作推理器(EAR)和隐式动作推理器(IAR)在多个数据集上超越了目前最先进的模型。
2.Why?
现有的通用策略主要在视觉-语言(输入)空间中进行思考,往往难以充分应对这些丰富的语义表征与精确、低层级的动作执行(输出)需求之间的固有差异。VLA模型视觉语言模型主干中所编码的知识源自专注于语义对齐与问答的网络大规模数据集预训练,虽能产出针对语言理解优化的表征,却无法捕捉物理动态特性。同样,尽管世界模型能基于输入预测未来视觉状态,其指导仍受限于自然视觉表征。
近期研究引入了显式的中间推理——例如子任务预测(语言)或目标图像合成(视觉)——以指导动作生成。然而,这些中间推理通常是间接的,且本质上难以传递精确动作执行所需的完整、细粒度信息。
3.How?
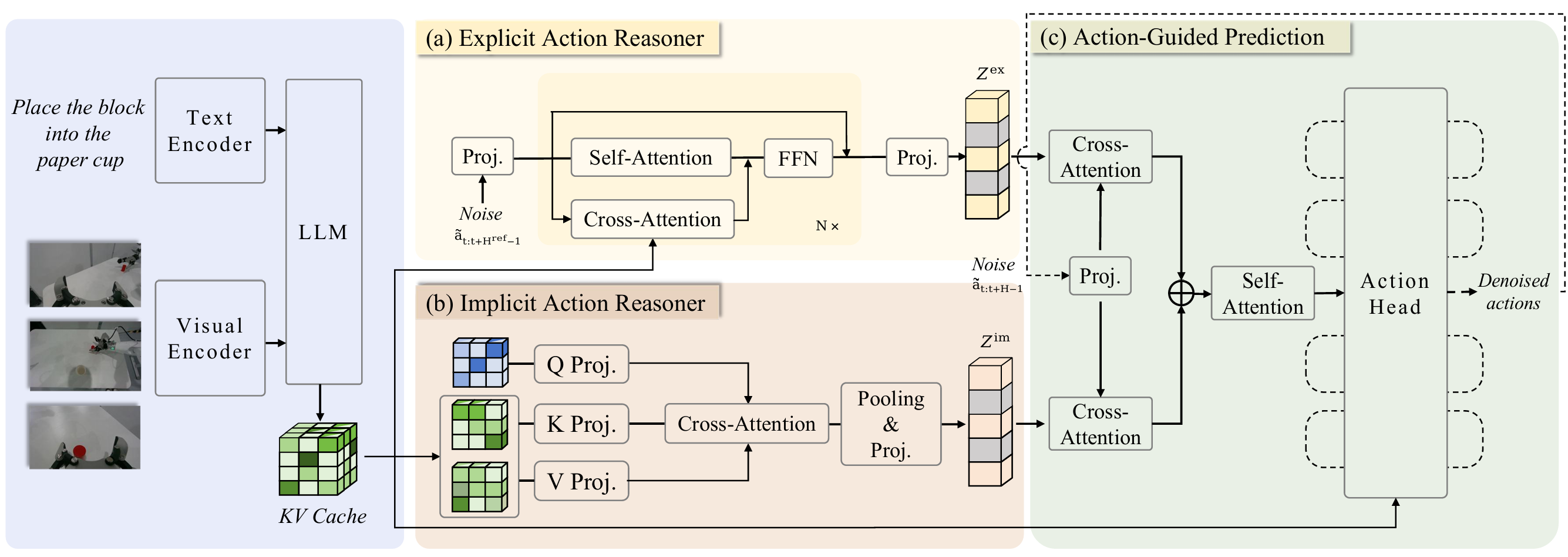
动作推理分为两种形式:显式与隐式
显式形式对应可观测的运动轨迹(如人类演示数据),直接编码可执行的行为模式;
隐式形式则存在于潜在线索中,例如“伸手”或“抓握”等语言表达,以及视觉情境中蕴含的交互意图。
显式动作推理器,其以轻量级Transformer实现,能基于多模态观测合成粗粒度运动轨迹,在动作空间内提供直接可执行的指导。
隐式动作推理器,通过对下采样后的多模态表征与可学习查询进行交叉注意力建模,从而推断潜在的动作先验,提供隐式行为先验。
动作引导预测头通过交叉注意力协同整合显式与隐式指导信息,以条件化最终的去噪过程,生成可执行动作序列。
4.Takeaways:
这个模型是基于
局限性&未来工作:
推理模块引入了额外的计算成本——虽然相较于性能增益较为有限,但可能对资源受限的机器人平台部署构成挑战。此外,当前学界主流的动作表征多采用动作块形式(即关节角度或末端执行器位姿等底层控制指令序列),此类表征虽能忠实编码执行动作,却缺乏便于高层空间推理(如以物体为中心的协调或接触几何关系)的显式几何结构。因此,动作思维链推理的潜力可能未能完全释放。
未来研究可通过增强具有空间grounded信息的动作表征,使动作思维链能在几何可解释的3D空间中运作,这是一个值得探索的前沿方向。
ACoT-VLA | arxiv 2026.01.16 | Paper Reading